“Bez SQLa się nie da” - spojrzenie w stronę Trino - część 2

W poprzedniej części próbowaliśmy analizować pewne dane, które fizycznie przechowywane są w bazie danych Cassandra. Cassandra, ze swojej natury, jest bazą “query oriented” - zapiszmy dane w takiej postaci, żebyśmy potrafili odpowiedzieć na z góry ustalone pytania.
Wstęp, czyli generujemy kolejne problemy
Wykorzystaliśmy Trino, żeby odpowiedzieć na pytania, na które nasza baza (czyli zaprojektowania struktura) nie jest gotowa. Zasadność takiego wykorzystania Trino można łatwo obalić. “Rzeczywiście, może nie wszystko wyszło tak jak należy, ale to da się naprawić”. Skoro potrzebujemy odpowiedzi na określone powtarzalne zapytania to trzeba wydrukować sobie diagram porównujący Relational Data Modeling i Cassandra Data Modeling, powiesić na ścianie i skupić się na prostokącie Application Workflow. Czy zatem wykorzystanie Trino pozostaje nam tylko do okazjonalnych, jednorazowych zapytań? Albo do testowej czy serwisowej weryfikacji danych?
Spróbujmy zrobić coś “trudniejszego”! Połączymy dwie tabele albo, to lepiej brzmi, wykonamy operację typu join. [I teraz abstrakcyjne postacie, nazwijmy je Witek i Robert, które od lat przewalają miliony wierszy “sqlami” na kilka stron pokładają się ze śmiechu].
Załącznikiem do wpisu jest repozytorium git, które zawiera kompletne środowisko.
Do uruchomienia potrzebujemy “jedynie” Dockera.
git clone github.com/cafebabepl/blog-bez-sqla-sie-nie-da-spojrzenie-w-strone-trino.git
cd blog-bez-sqla-sie-nie-da-spojrzenie-w-strone-trino
git checkout czesc-2
docker-compose -p blog up -d
Byłby monolit, nie byłoby problemu
Nasz “system” się rozwija. “Spokojnie, zaraz się rozkręci…” Właśnie dorzucamy kolejne komponenty, moduły, klocki więc spróbujmy to jakoś nazwać (a wiadomo, że to nie są rzeczy łatwe).
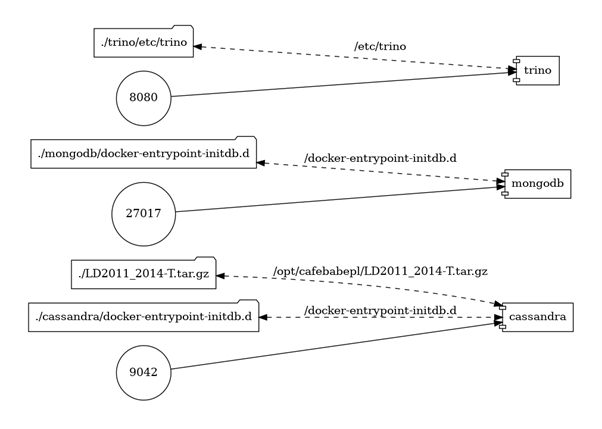
To co mamy do tej pory, czyli bazę danych Cassandra, która zawiera informacje o zużyciu energii elektrycznej dla wybranych punktów poboru/klientów w Portugalii w okresie 2011-2014 nazwijmy “repozytorium danych odczytowych”. Repozytorium to nie zawiera żadnych informacji o samych punktach poboru czy klientach.
Architekci jednak przewidzieli potrzebę ewidencji punktów poboru więc ktoś zaprojektował komponent o nazwie… “ewidencja punktów poboru”. Na potrzeby naszych rozważań jest to baza danych MongoDB.
Przykładowy zestaw danych ładowany jest z pliku \mongodb\docker-entrypoint-initdb.d\mt.jsonl. Jest to tzw. “dżejsonlajn” - cały plik nie jest poprawnym JSON, ale każda pojedyncza linia jest poprawnym JSON. Plik został wygenerowany z wykorzystaniem m.in. biblioteki java-faker (https://github.com/DiUS/java-faker) i “lokalami” portugalskimi oraz załadowany do bazy poleceniem mongoimport.

Jak podłączyć się do naszej bazy MongoDB?
Baza MongoDB uruchomiona jest na porcie 27017. Aby się do niej podłączyć możemy wykorzystać choćby aplikację MongoDB Compass (adres localhost:27017)
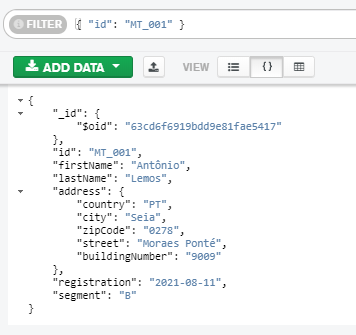
(przykładowy dokument wyszukany w aplikacji MongoDB Compass)
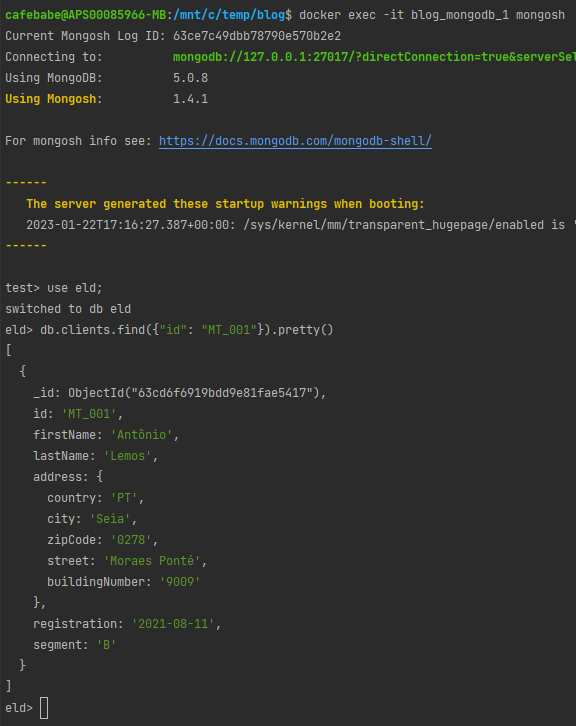
albo uruchomić klienta mongosh w obrazie:
W Trino mamy też już zdefiniowany katalog o nazwie mongodb. Konfiguracja określona jest w pliku \trino\etc\trino\catalog\mongodb.properties.
Jak podłączyć się do naszego Trino?
Trino uruchomione jest na porcie 8080. Aby się podłączyć do “klastra” można użyć dowolnego klienta, który wspiera Trino, wykorzystać dostarczanego CLI, np.
![]()
albo uruchomić klienta na naszym koordynatorze, np.
![]()
Spróbujmy zweryfikować strukturę tabeli clients, która wprost mapuje się na kolekcję clients w bazie dokumentowej:
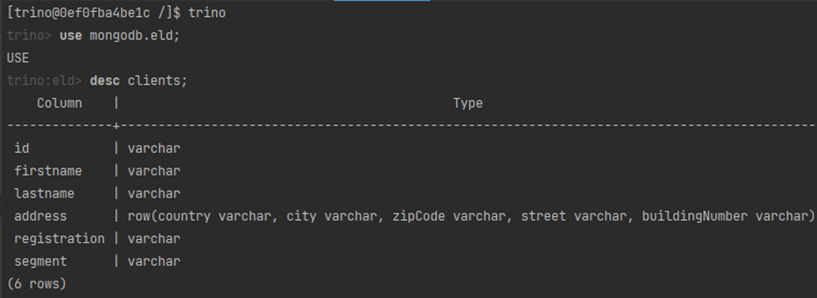
Warto chyba zwrócić uwagę na sposób mapowania MongoDB → Trino: kolekcji na tabele i samych typów. Pole address jest typu Object (zawiera pola z kodem kraju, nazwą miejscowości itd.) zostało zmapowane na typ ROW. Dzięki temu możemy wykonać np. zapytania postaci
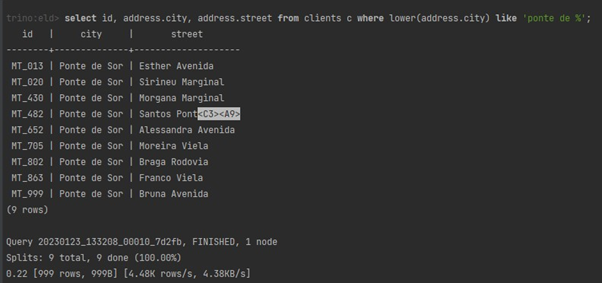
nie martwiąc się o samą strukturę pierwotnego obiektu (JSON).
“Jakbym chciał bez joina, to bym chyba powiedział poproszę bez joina, nie!?”
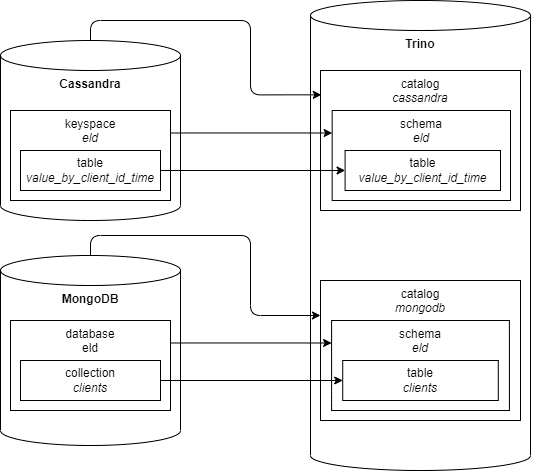
Podsumujmy zatem naszą rozproszoną strukturę bazy danych:
“repozytorium danych odczytowych” jako baza danych Cassandra, keyspace eld i tabela value_by_client_id_time, które mapują się w Trino na katalog cassandra, schemat eld i tabelę value_by_client_id_time, “ewidencja punktów poboru” jako baza danych MongoDB, baza eld i kolekcja clients, które mapują się w Trino na katalog mongodb, schemat eld i tabelę clients.
Wpada teraz jakiś abstrakcyjny analityk, product owner czy ktokolwiek, który obiecał klientowi “Raport zużycia z uwzględnieniem segmentacji punktu poboru”. Bo klient planuje akcję marketingową albo nic nie planuje ale handlowiec wytworzył w nim taką potrzebę.
W ramach pierwszej próby odparcia ataku mówimy, że “się nie da” bo zużycia mamy w “repozytorium danych odczytowych” a ten komponent nic nie wie o punktach poboru. Segmentację mamy określoną w “ewidencji punktów poboru” ale tam nie mamy żadnych agregatów zużyć. Ale pewnie wróci…
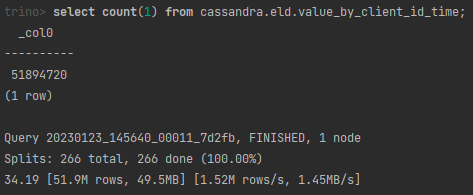
Zweryfikujmy na początek nasze “repozytorium danych odczytowych”.
Liczba wierszy…
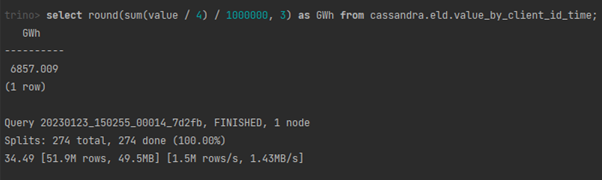
… i sumaryczne zużycie.
I “nadszedł moment, w którym musisz wziąć sprawy w swoje ręce” więc spróbujmy
by “za chwilę” otrzymać wynik:
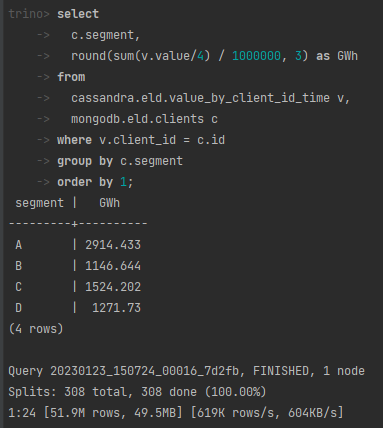
I nawet suma się zgadza!
To przecież “proste” zapytanie, które w “prosty” sposób łączy dwie tabele i wykonuje “prostą” operację grupowania.
Co dalej?
Udało nam się połączyć dane z dwóch całkowicie różnych baz danych, z własnymi językami zapytań, za pomocą jednego spójnego interfejsu zapytań SQL. Niezależnie od koncepcji tych baz odwołujemy się do danych jak do “normalnych” tabel dobrze znanych z relacyjnych baz danych. W kolejnej części spróbujemy się zmierzyć z jeszcze bardziej “pokręconą” bazą danych. “Wjedzie” Apache Kafka! Nasz system zostanie rozbudowany o kolejny komponent, który będzie zbierał zdarzenia pochodzące z urządzeń a kolejna abstrakcyjna postać będzie potrzebować jakichś statystyk. I znowu “trzeba” będzie wykonać “sqla”. I znowu coś z czymś połączyć. “To wysoko postawiona poprzeczka”!
