Cache’owanie w Springu z wykorzystaniem Redisa

Podstawową zaletą pamięci podręcznej cache jest szybki zapis oraz odczyt danych, które mają być przetworzone przez system w bliskiej perspektywie czasu. Pozwala na znaczną optymalizację wykonania operacji wymagających pobierania danych, o czym przekonamy się niebawem.
Redis jest strukturą przechowującą w pamięci RAM dane typu klucz-wartość, dzięki czemu jest niesamowicie wydajna. Często wykorzystuje się ją jako bazę danych, broker wiadomości lub właśnie jako cache.
W tym artykule skonfigurujemy Redisa jako cache dla aplikacji Spring Boot, przetwarzającej dane albumów muzycznych.
Uwaga: Całość prezentowanego kodu można podejrzeć tutaj.
Konfiguracja środowiska – Docker + Redis
1. Uruchomimy Redisa lokalnie, dlatego będziemy potrzebować zarówno Dockera, jak i kontenera Redisa. Aby zainstalować Dockera, należy przejść jedną ze ścieżek instalacji, adekwatną do używanej platformy.
2. Mają zainstalowanego Dockera możemy przejść do pobrania obrazu Redisa, dostępnego na oficjalnej stronie. W tym celu, w wierszu poleceń, wykonujemy komendę, która pozwala na pobranie aktualnego obrazu Redisa.
docker pull redis
3. Uruchamiamy kontener Redisa (cache-demo-redis) za pomocą polecenia docker run:docker run --name cache-demo-redis -d redis
Konfiguracja środowiska – Kotlin & Spring Boot
1. Tworzymy nowy projekt. Na potrzeby prezentacji zdecydowałam się na projekt w Kotlinie, bazujący na Gradle. IntelliJ ® New Project ®Kotlin ® Application
2. Dodajemy do build.gradle.kts pluginy i zależności SpringBoot, dzięki którym będziemy mogli uruchomić aplikację jako aplikację Springową:
kotlin("jvm") version "1.5.10"
id("org.springframework.boot") version "2.5.4"
id("io.spring.dependency-management") version "1.0.11.RELEASE"
}
dependencies {
implementation("org.springframework.boot:spring-boot-starter-web")
testImplementation(kotlin("org.springframework.boot:spring-boot-starter-test"))
}
@SpringBootApplication
open class RedisCacheDemoApplication
fun main(args: Array<String>) {
runApplication<RedisCacheDemoApplication>(*args)
}
Wdrożenie Redisa w aplikacji Springowej
Zaczniemy od dodania zależności spring-boot-starter-cache oraz spring-boot-starter-data-redis do projektu w build.gradle.kts.
implementation("org.springframework.boot:spring-boot-starter-cache")
implementation("org.springframework.boot:spring-boot-starter-data-redis")
Nadszedł czas konfiguracji Redisa w aplikacji w taki sposób, aby była w stanie skorzystać z uruchomionego wcześniej kontenera. Można to zrobić na kilka sposobów, np. poprzez ustawienie odpowiednich wartości w resources/application.yaml (i to jest w zasadzie jedna z podstawowych, najprostszych opcji).
Domyślnie Redis korzysta z portu 6379, stąd taka wartość w poniższej konfiguracji:
spring:
redis:
host: localhost
port: 6379
cache:
type: redis
Co więcej, sama konfiguracja Redisa w tym pliku może ograniczyć się do zdefiniowania odpowiedniego URL z uwzględnieniem podstawowych parametrów:
spring:
redis:
url: redis://[USER]:[PASSWORD]@[CLUSTER-PUBLIC-IP]:[PORT]
Implementacja klas
Podstawowe modele
Załóżmy, że nasza aplikacja będzie odpowiedzialna za przetwarzanie danych albumów muzycznych. W związku z tym warto zacząć od podstawowych modeli, tj. Album reprezentująca pojedynczy album muzyczny, który posiada autora, tytuł oraz listę piosenek Song. Każda z piosenek z kolei ma nadany tytuł.
data class Album(
val author: String?,
val title: String?,
val songs: List<Song>?
) {
constructor() : this(null, null, null)
}
data class Song(
val title: String?
) {
constructor() : this(null)
}

Repozytorium Albumów
Do celów samej prezentacji ograniczę się do statycznego ustawienia kilku przykładowych wartości dla naszych albumów muzycznych. Postawiłam więc na 3 (z wielu) moich ulubionych wykonawców – mam nadzieję, że ten wybór przypadnie Wam do gustu :)
@Component
open class AlbumRepository {
private val albums = listOf(
Album("Queen", "A Night At The Opera", listOf(
Song("Lazing on a Sunday"),
Song("You're My Best Friend"),
Song("Sweet Lady"),
Song("Bohemian Rhapsody")
)),
Album("Dzem", "Cegla", listOf(
Song("Czerwony jak cegla"),
Song("Whisky"),
Song("Nieudany skok"),
Song("Powiał boczny wiatr")
)),
Album("Nothing But Thieves", "Broken Machine", listOf(
Song("I Was Just a Kid"),
Song("Amsterdam"),
Song("Sorry"),
Song("Soda")
)),
)
@Cacheable(cacheNames = ["albumsCache"])
open fun getAlbumByTitle(title: String): Album {
print("getAlbumByTitle repository call.\n")
return albums.first { it.title?.trim()?.lowercase() ==
title.trim().lowercase() }
}
@Cacheable(cacheNames = ["songsCache"], key = "#title")
open fun getSongsByAlbumTitle(title: String): List<Song> {
print("getSongsByAlbumTitle repository call.\n")
return albums.first { it.title?.trim()?.lowercase() ==
title.trim().lowercase() }.songs
?: error("No songs found for provided album.")
}
}
Zwróćcie uwagę na adnotacje @Cacheable. To właśnie dzięki niej można zdefiniować w jakim cache’u (po nazwie/nazwach cacheNames) oraz pod jakim kluczem (key) ma się znajdywać przechowywana wartość. Nazwy mogą służyć do określenia docelowej pamięci podręcznej (lub pamięci podręcznych), pasującej do wartości kwalifikatora lub nazwy Beana określonej definicji Beana.
Jeśli chodzi o definiowanie klucza to, jak się na pewno domyślacie, mamy do wyboru kilka ścieżek. Domyślnie brane są wartości parametrów wejściowych metody, a następnie serializowane do Stringa. Możemy też zdefiniować klucz z wykorzystaniem języka Spring Expression Language (SpEL), np.
key = "'Title:'.concat(#title).concat(':Author:').concat(#author)"
Możemy w końcu zdefiniować też generator klucza specyficzny dla każdej z metod, które go wykorzystają. Aby to zrobić, implementuje się klasę implementującą interfejs KeyGenerator, np.
class AlbumKeyGenerator: KeyGenerator {
override fun generate(target: Any, method: Method, vararg params: Any?): Any {
return params.mapNotNull { it as String? }.joinToString { ":" }
}
}
class ApplicationConfig: CachingConfigurerSupport() {
@Bean("albumKeyGenerator")
override fun keyGenerator(): KeyGenerator? {
return AlbumKeyGenerator()
}
}
@Cacheable(cacheNames = ["songsCache"], keyGenerator = "albumKeyGenerator")
UWAGA
Istotne jest to, żeby definicje metod, których zwracane wartości mają być przechowywane, znajdowały się w innej klasie niż ta, w której są wywoływane. Gdybym definicję repozytorium rozszerzyła np. o metodę.
fun isSongExistsInAlbum(albumTitle: String, songTitle: String): Boolean {
return getSongsByAlbumTitle(albumTitle).map { it.title }
.contains(songTitle)
}
Dzieje się tak, ponieważ Spring tworzy proxy dla naszego Beana i obsługuje cache’owanie, gdy wywołanie metody przechodzi przez ten proxy. Jeśli wywołanie funkcji jest natomiast wykonywane wewnętrznie, Spring nie przekazuje proxy, a zatem cache’owanie nie jest stosowane.
Serwis pobierający dane z repozytorium
Jak wspomniałam wyżej – ważne, żeby funkcja do cache’owania została wywołana z klasy zewnętrznej. W związku z czym wywołamy je sobie w odrębnej klasie AlbumService, zdefiniowanej następująco:
@Service
open class AlbumService(
private val albumRepository: AlbumRepository
) {
open fun getAuthorByAlbumTitle(title: String): String {
print("Author retrieval run.\n")
return albumRepository.getAlbumByTitle(title).author ?: error("Author for provided album name not found.")
}
open fun getSongsByAlbumTitle(title: String): List<String> {
print("Songs retrieval run.\n")
return albumRepository.getSongsByAlbumTitle(title).mapNotNull { it.title }
}
}
Kontroler
Nie może również zabraknąć kontrolera, do którego sięgniemy po interesujące nas dane.
@RestController
@RequestMapping("/albums")
class AlbumController(
private val cachedAlbumService: AlbumService
) {
@GetMapping("/{title}/songs")
fun getSongs(@PathVariable title: String):
ResponseEntity<List<String>> =
ResponseEntity.ok(cachedAlbumService.getSongsByAlbumTitle(title))
@GetMapping("/{title}/author")
fun getAlbumByTitle(@PathVariable title: String):
ResponseEntity<String> =
ResponseEntity.ok(cachedAlbumService.getAuthorByAlbumTitle(title))
}
Konfiguracja Cache
Redis całkiem nieźle radzi sobie z przechowywaniem danych prostych typów, więc w przypadku przechowywania pojedynczych wartości String, Int, itp. na tym etapie moglibyśmy zakończyć implementację. Jednak co w sytuacji, gdy będziemy chcieli przechować kolekcje danych lub złożone obiekty w pamięci podręcznej? Czy Redis podoła zadaniu bez dodatkowej konfiguracji? Przekonajmy się na przykładzie dwukrotnego wywołania usługi (przez wzgląd na to, że dopiero za drugim razem zaglądamy do pamięci cache):
GET localhost/albums/Cegla/songs
Niestety, w tej sytuacji otrzymamy błąd serializacji danych, widoczny poniżej. W związku z tym czeka nas konfiguracja własnego serializatora, który uwzględni interesujące nas typy.
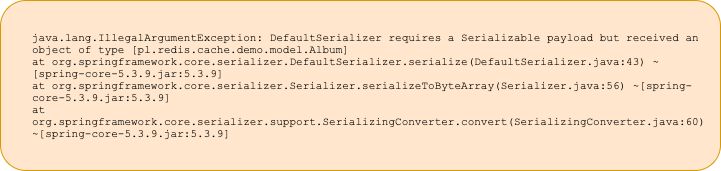
Pełną konfigurację zaprezentowano w poniższej klasie konfiguracyjnej RedisConfiguration
@Configuration
open class RedisConfiguration {
@Bean
open fun redisCacheConfiguration(): RedisCacheConfiguration {
val serializer = GenericJackson2JsonRedisSerializer(redisObjectMapper())
return RedisCacheConfiguration
.defaultCacheConfig()
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(serializer))
}
private fun redisObjectMapper(): ObjectMapper {
val polymorphicTypeValidator = BasicPolymorphicTypeValidator.builder()
.allowIfSubType(Album::class.java)
.allowIfSubType(Song::class.java)
.allowIfSubType(List::class.java)
.build()
return ObjectMapper().apply {
activateDefaultTyping(polymorphicTypeValidator, ObjectMapper.DefaultTyping.EVERYTHING, JsonTypeInfo.As.PROPERTY)
}
}
}
PolymorphicTypeValidator, to interfejs dla klas, które obsługują walidację podtypów opartych na nazwie klasy, wykorzystywanych w deserializacji polimorficznej – dzięki dodaniu paru wywołań allowIfSubType jesteśmy w stanie pozwolić na serializację/deserializację obiektów wskazanych typów oraz uniknąć błędu następującej postaci:

Jakiego wyniku się spodziewamy?
Przyjrzyjmy się pokrótce poniższej ilustracji. Całkiem nieźle obrazuje jak działa cache’owanie. W sytuacji, gdy wywołamy nasze usługi po raz pierwszy:
- Zajrzymy do cache, gdzie jeszcze nie postanowiliśmy nic przechować, więc tak naprawdę stwierdzimy, że w cache nie ma tego, czego szukamy.
- Będziemy zmuszeni sięgnąć po dane do repozytorium. Właśnie w tym momencie zostaną one pobrane i automatycznie zachowane w cache’u. W związku z tym, gdy będziemy chcieli pobrać dane pod tym konkretnym kluczem, nie będziemy musieli wracać do repozytorium, ponieważ będziemy w stanie wyciągnąć je z pamięci podręcznej.
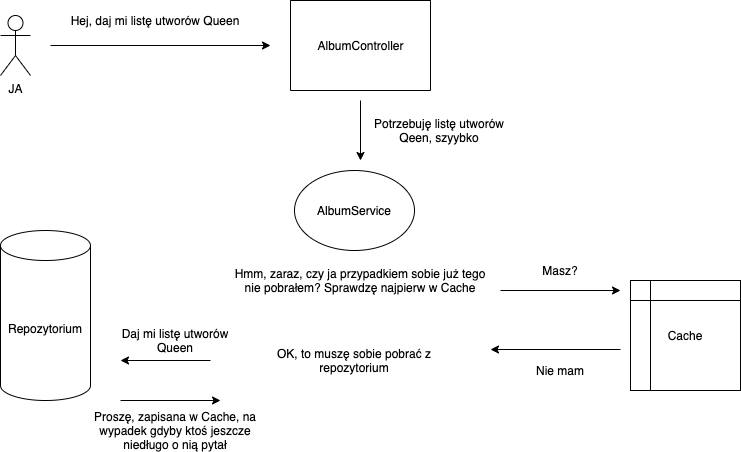
Rys.1. Krótka historia zapytania o listę utworów Queen :)
Zerknijmy więc na wywołanie metody:
GET http://localhost:8080/albums/Cegla/author

Nietrudno zauważyć, że za drugim razem nie wchodzimy ponownie do metody repozytorium getAlbumByTitle. Dla pewności zajrzałam również do samego Redisa i za pomocą polecenia:
redis-cli KEYS *
Wygląda na to, że nasza aplikacja działa poprawnie :)
Wnioski
Spring oferuje mnóstwo możliwości na wdrożenie cache. W ramach tego artykułu zaprezentowałam Wam jeden z najbardziej podstawowych przypadków wymagających obsłużenia.
