Hadoop dla .NET Developerów w przykładach dla .NET Core Część 2

Jak pisałem w podsumowaniu poprzedniej części w obecnej ubrudzimy sobie ręce skupiając się na pisaniu programów w paradygmacie MapReduce.
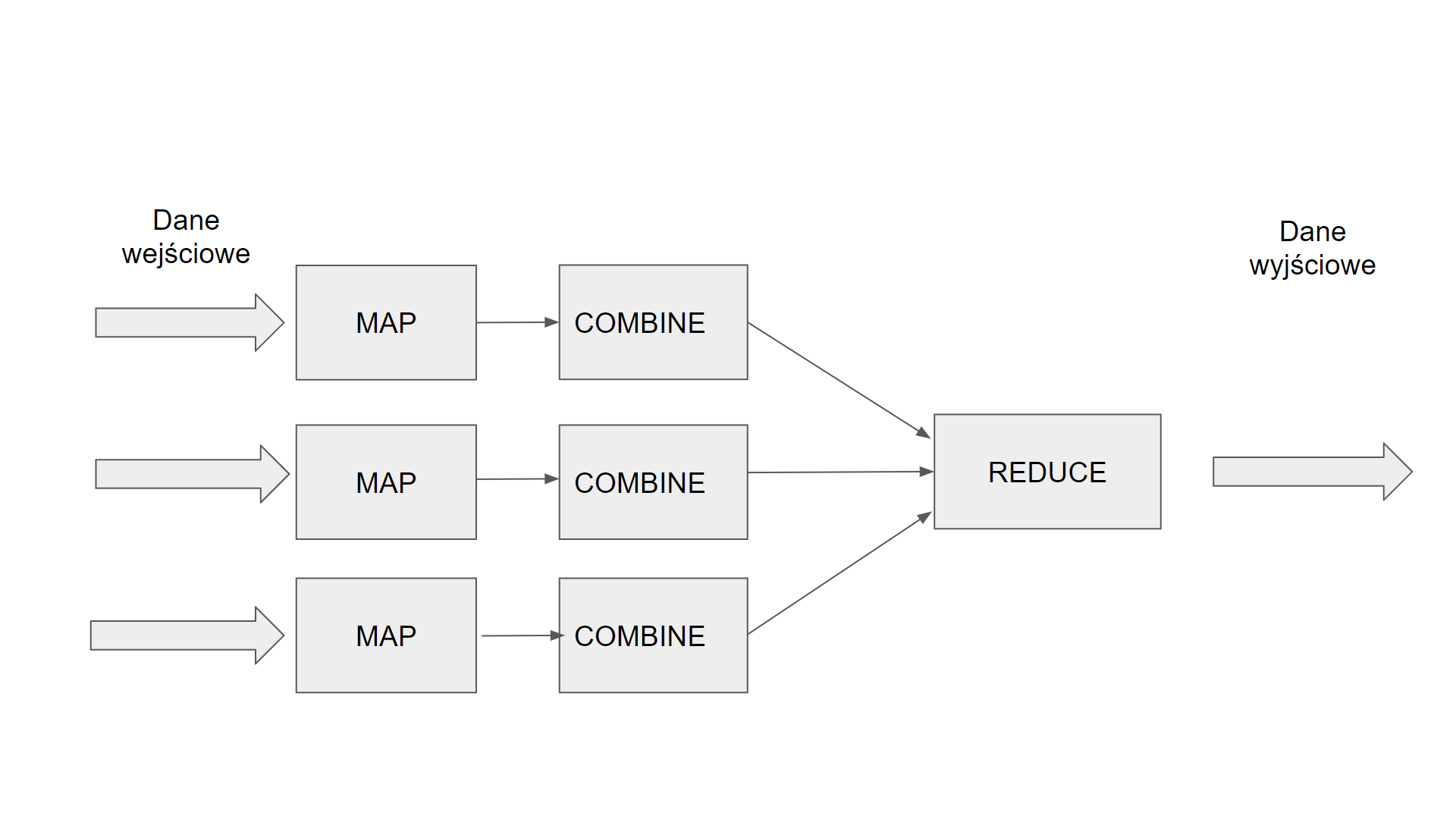
Zacznijmy od przypomnienia jak wygląda schemat działania MapReduce. Jak widać na schemacie 1 możemy wyróżnić następujące części:
- Map - program mapujący dane wejściowe)
- Reduce - reduktor danych zbierający ostateczny wynik)
- Combiner - kombinator zwany pół reduktorem zbierający dane pośrednie pisany w celu optymalizacji procesu)
- Driver – program konfigurujący w którym określamy jakiego programu Map, Reduce , Combiner będziemy używać oraz inne parametry całego procesu takie jak katalog wejściowy na HDFS , katalog wyjściowy na HDFS, inne parametry np. takie jak liczba użytych programów Map itp
Schemat 1
MapReduce w Javie
Do pisania programów MapReduce w Javie przygotowano specjalne API. Sposób pisania MapReduce pokażemy na przykładzie prostego programu , który liczy liczbę wystąpień danego słowa w podanym tekście.
W celu utworzenia programu Map Tworzymy klasę dziedziczącą po klasie Mapper:
public class Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
Map przyjmuje parę klucza ( o typie KEYIN) oraz wartości (o typie VALUEIN) i zwraca kolekcje par klucza (o typie KEYOUT) oraz wartości(VALUEOUT). Przykrywamy metodę która przyjmuje klucz oraz wartość dla tego klucza oraz zwracamy wyniki za pomocą klasy Context :
protected void map(KEYIN key, VALUEIN value, org.apache.hadoop.mapreduce.Mapper.Context context)
W naszym przykładzie klucz wejściowy będzie stanowił numer linii a wartością będzie tekst zawarty w jednej linii. Jako dane z Map będziemy zwracać klucz , który będzie stanowił pojedynczy wyraz a wartość liczność jego wystąpienia czyli 1.
Przykład implementacji poniżej:
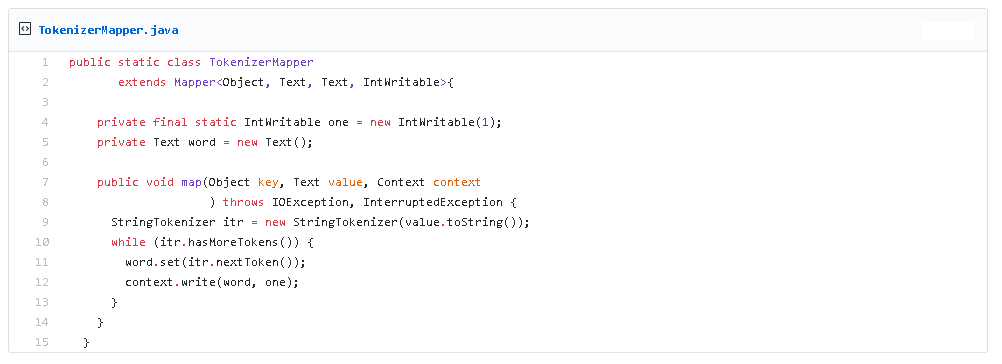
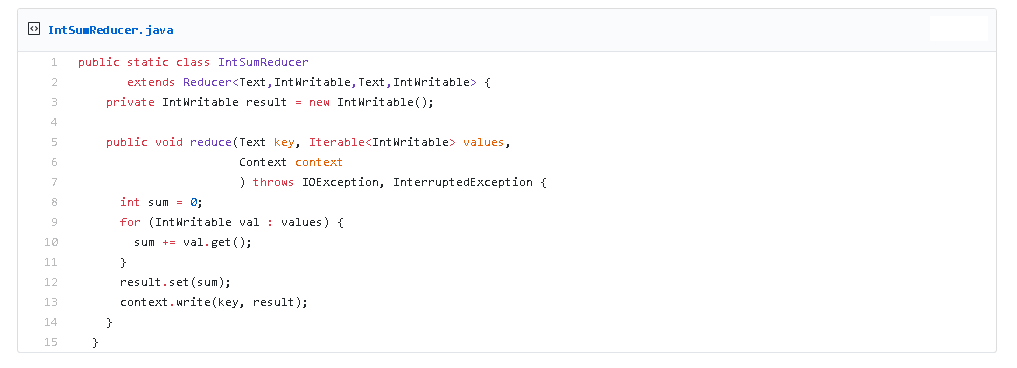
W przykładzie pokazanym poniżej klucz wejściowy stanowi słowo a wartość kolekcja zawierająca liczbę jeden dla każdego wystąpienia słowa w kluczu. Agregujemy wartości dla każdego klucza i zwracamy słowo oraz liczbę wystąpień tego słowa.
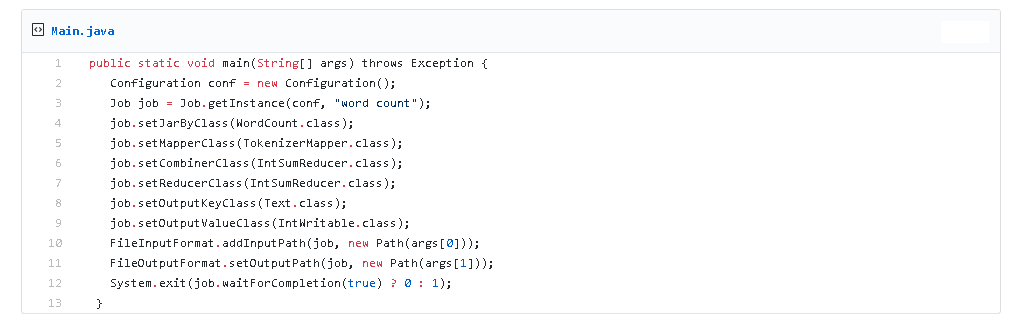
Ostatnim elementem który musimy stworzyć jest program Driver , który jest uruchamialną klasą Java z klasą Main. Określamy w niej konfiguracje takie jak :
- Klasę Mapper
- Klasa Combiner
- Klasa Reducer
- Ścieżka wejściowa z której odczytywany są pliki do przetwarzania
- Ścieżka wyjściowa do której piszemy pliki powstałe w wyniku przetwarzania
- Ilość instancji Mappera , Combinera i Reducera
Implementację naszego przypadku widzimy na listingu poniżej:
MapReduce w .NET Core
Hadoop daje możliwość pisania programów w językach innych Java za pomocą Hadoop Streaming. W tym celu należy napisać programy Mapper , Reducer oraz Combiner , które czytają ze standardowego wyjścia i piszą na standardowe wyjście. Do obsługi błędów w przetwarzaniu przewidziano także pisanie do standardowego wyjścia w błędu. Błędy powinny być zwracane w specjalnym formacie wyjściowym. Informacje o tym odnajdziemy na stronie Hadoop w sekcji dotyczącej streamingu.
W celu uruchomienia takiego programu na klastrze Hadoop należy zapewnić skryptowi środowisko uruchomieniowe na węzłach klastra. W przypadku C# w .NET Core jest to instalacja środowiska uruchomieniowego .NET Core SDK na węzłach klastra. Przedstawiony w poprzedniej części klaster w kontenerach Docker posiada już zainstalowane takie środowiska uruchomieniowe .NET Core SDK w wersji 2.2 dla każdego węzła.
Przykładowy program , który napiszemy w .NET Core oparty będzie o dane pozyskane z bazy GUS. Jest to plik w którym zapisane są ulicy występujące w danym województwie, gminie, powiacie, miejscowości etc. Naszym zadaniem będzie napisanie programu MapReduce który policzy występowanie nazwy danej ulicy. Określimy ranking najpopularniejszych nazw ulic w Polsce. Struktura pliku w formacie CSV pozyskana z GUS wygląda następująco:
WOJ;POW;GMI;RODZ_GMI;SYM;SYM_UL;CECHA;NAZWA_1;NAZWA_2;STAN_NA 04;01;04;2;0857344;18588;ul.;Relaksowa;;2019-02-18 04;01;04;2;0857344;22036;ul.;Szosa Ciechocińska;;2019-02-18 04;01;04;2;0857605;07122;pl.;Jana Pawła II;;2019-02-18
W przetwarzaniu w programie MapReduce interesuje nas trzy kolumny CECHA,NAZWA1,NAZWA2 oraz częstość występowania razem tej trójki. Cały prezentowany kod poniżej odnajdziemy na github:
https://github.com/mrozim78/hadoop-net-presentation
w katalogu mapreduce.
Rozpoczniemy od napisania programu Map. Jak widzimy na schemacie 2 program powinien wybierać kolumny CECHA, NAZWA_1,NAZWA_2 (przez połączenie ich ze spacją) - co będzie stanowiło nasz klucz oraz dodanie do tego po znaku tabulacji wartości 1 jako wartości dla tego klucza (liczba wystąpień klucza). Znak tabulacji będzie stanowił separator między kluczem oraz wartością.
Schemat 2
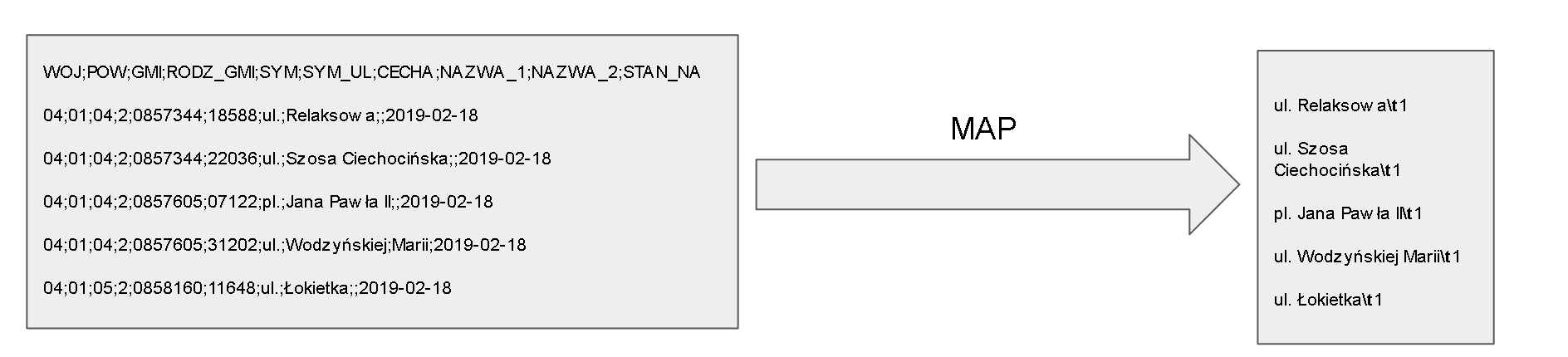
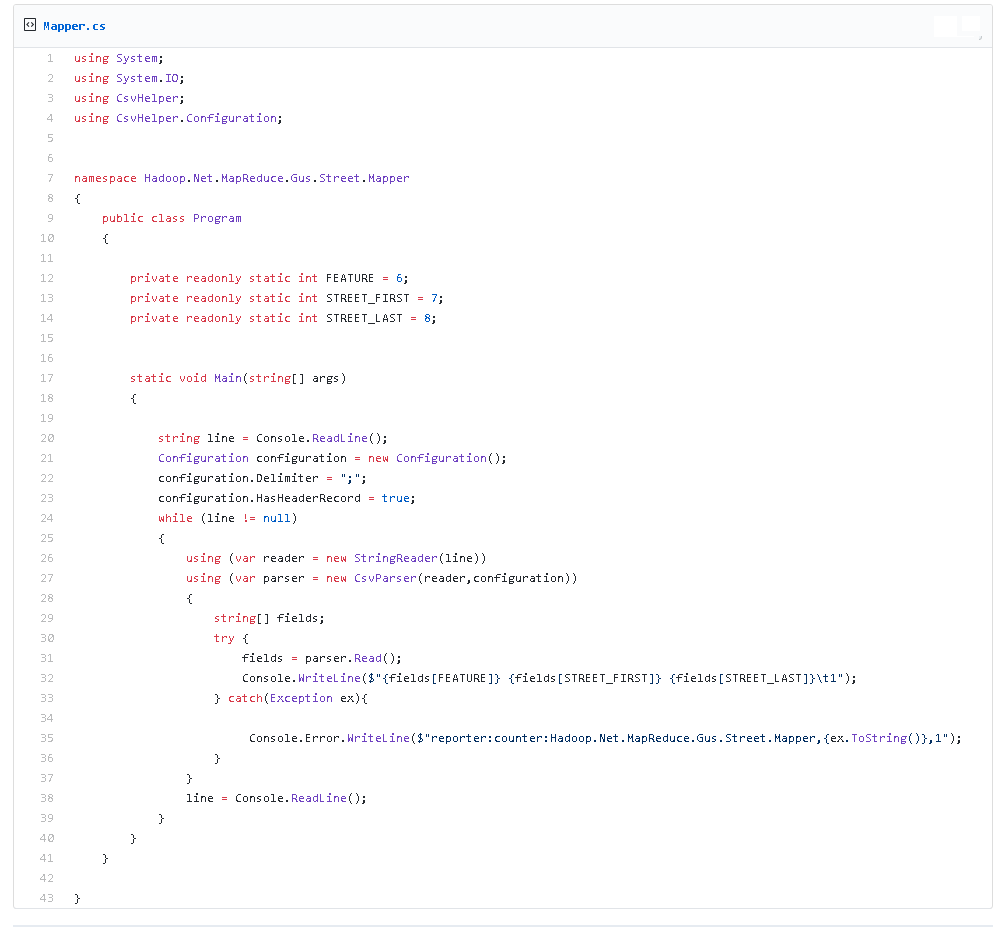
Poniżej listing programu Map:
Program Reduce oraz Combine na wejście otrzymuje parametry sformatowane jak na wyjściu funkcji Map (klucz tabulacja wartość) które są ponadto posortowane przez framework Hadoop na wejściu do Reduce oraz Combine po kluczu (w naszym wypadku klucz stanowi nazwa ulicy). Reduce oraz Combine grupuje wpisy po kluczu oraz dodaje liczbę zawartą w wartości dla danego klucza. Wynik ostateczny z funkcji Reduce funkcja frameworkowa Hadoop sortuje po kluczu. Sposób działania tych programów jest widoczny na schemacie 3.
Schemat 3
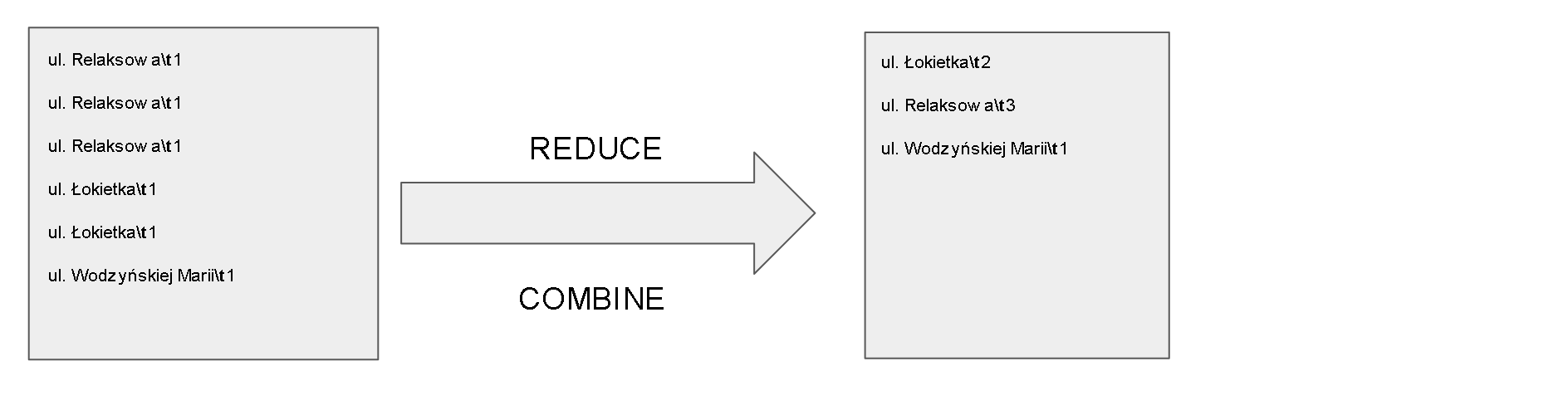
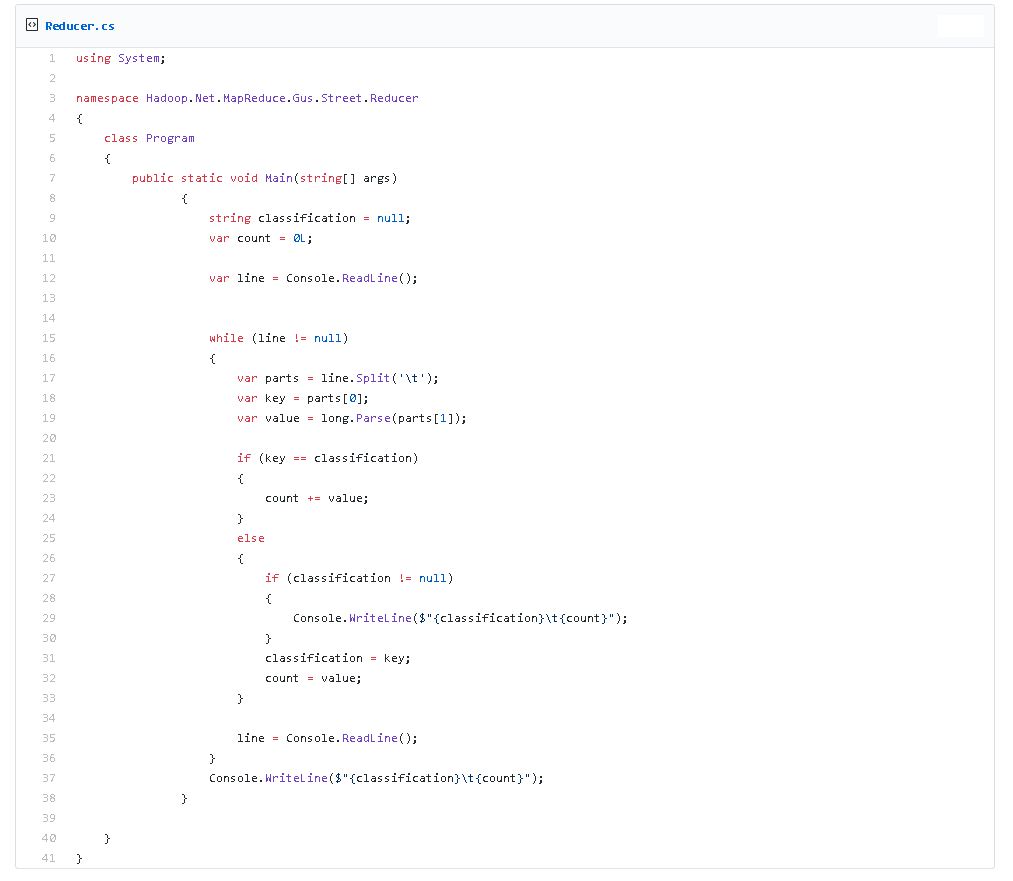
Poniżej listing programu Reduce oraz Combine:
Ja widać ze schematu 3 wynik z pierwszej funkcji MapReduce posortowany jest po kluczu(nazwie ulicy). Dla uzyskania ostatecznego wyniku potrzebujemy posortowania po wartości (liczby wystąpień). W tym celu piszemy następny program MapReduce , który posortuje nam tak uzyskany wynik pośredni po wartości (liczbie wystąpień) a nie po kluczu (nazwie ulicy).
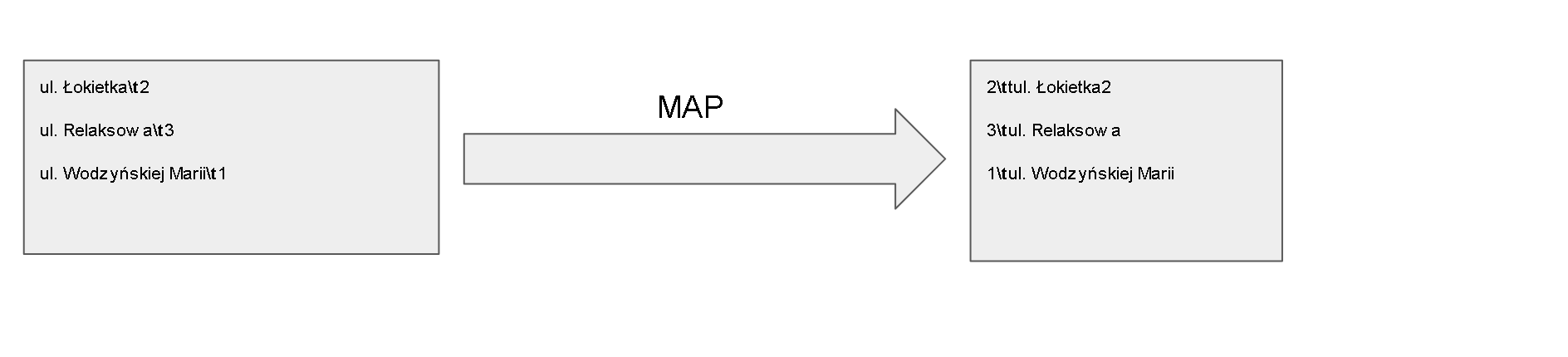
W tym celu zgodnie ze schematem 4 w nowym programie Map odwracamy klucz oraz wartość miejscami. Jako programu Reduce używamy funkcji identyczności (program dostarczany wraz z Hadoop) która nam tylko scali dane z mapowania a framework Hadoop wyjście z funkcji Reduce posortuje po kluczu czyli w naszym przypadku wartości wystąpień.
Schemat 4
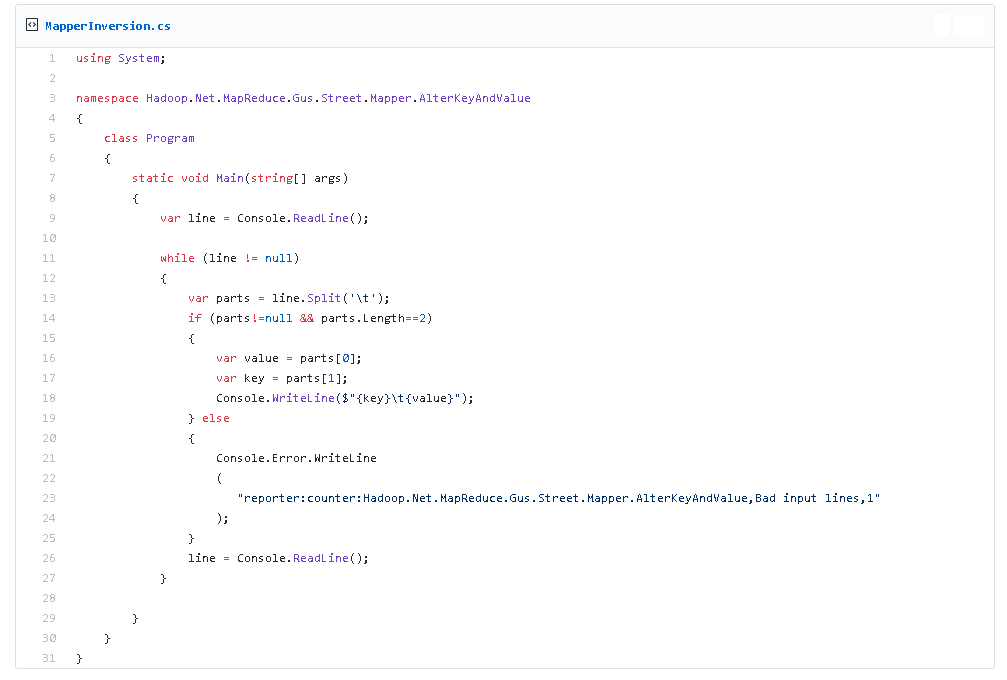
Poniżej listing programu mapującego:
Ponadto musimy podać w parametrach uruchomienia MapReduce jak sortować wartości liczbowe. W naszym przypadku będzie to kolejność malejąca oraz funkcja porównująca klucze powinna traktować klucz jako wartości liczbowe a nie standardowo jako wartości literowe. Program uruchamiamy w sposób następujący:
hadoop jar /opt/hadoop-2.7.7/share/hadoop/tools/lib/hadoop-streaming-2.7.7.jar \ -D mapreduce.job.output.key.comparator.class=org.apache.hadoop.mapreduce.lib.partition.KeyFieldBasedComparator \ -D mapred.text.key.comparator.options=-k1nr \ -files "mapreduce_publish" \ -mapper "dotnet mapreduce_publish/Hadoop.Net.MapReduce.Gus.Street.Mapper.AlterKeyAndValue.dll" \ -reducer org.apache.hadoop.mapred.lib.IdentityReducer \ -input /data/output/gus/step1 \ -output /data/output/gus/step2
Parametry -D stanowią dodatkową informację dla uruchomienia MapReduce. Pierwsza linia określa jaki komparator klucza powinien być wykorzystany w tym wypadku liczbowy a drugi określa kierunek sortowania w tym wypadku malejący. Wynik ostateczny odczytujemy z pliku z katalogu /data/output/step2
Podsumowując możemy zauważyć , że pisanie programów w MapReduce zarówno w Java jak i w innych językach jest dość prosta ale daje duże możliwości w przetwarzaniu dużych zbiorów danych. Nawet skomplikowane zadania przetwarzania można przedstawić jako łańcuch wywołań programów MapReduce.
W następnej części przybliżymy bazę HBase , która dane magazynuje na klastrze Hadoop. Pokażemy przykłady wykorzystania tej bazy w programach napisanych w .NET Core.
Galeria

Zobacz wszystkie artykuły tego autora