Jak usprawnić moje/Klienta procesy biznesowe?

Zarządzanie procesowe jest coraz bardziej popularnym podejściem w firmach. Zdecydowana większość dużych i średnich przedsiębiorstw oraz instytucji ma zdefiniowane i opisane swoje procesy biznesowe. Niestety, jak wskazuje praktyka, koszt opisania, a następnie aktualizacji tych procesów jest bardzo wysoki. Jednocześnie systematycznie rośnie stopień informatyzacji organizacji i większość procesów biznesowych jest w naturalny sposób wspomagana przez systemy IT.
Process Mining to metodyka, która wykorzystując zaawansowane algorytmy wizualizuje procesy biznesowe przedsiębiorstwa w oparciu o dane pobrane z jego systemów IT. Prezentowany jest faktyczny ich przebieg, a nie wyobrażenie osób opisujących proces. W konsekwencji możliwa jest analiza procesów pod kątem ich usprawniania.
Biorąc pod uwagę powyższe czynniki Process Mining jest często określany połączeniem dwóch nauk: Data Science i Process Science
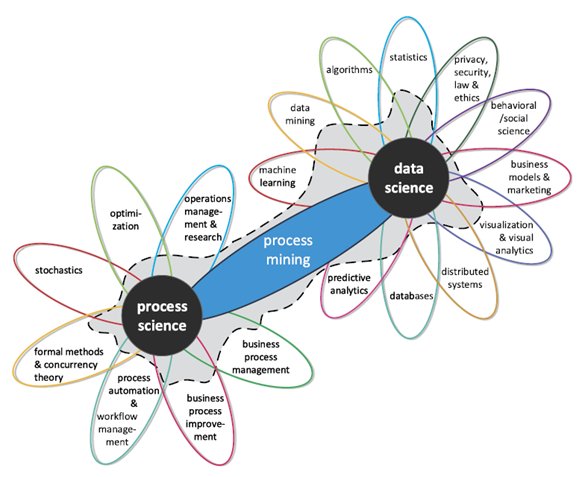
Rysunek 1 Obszary nauki powiązane z Process Mining. Źródło: (van der Aalst, 2016)
Źródłem danych wymaganych do budowy modelu biznesowego przez algorytmy PM są wszelkie systemy IT gromadzące informacje o przebiegu procesu biznesowego. Wymagana jest ekstrakcja tych danych i ich transformacja do postaci możliwej do automatycznej interpretacji. Log, który będzie wejściem do narzędzia PM, w wersji maksymalnie okrojonej powinien zawierać:
- unikalny identyfikator jednego przebiegu procesu – np. w procesie obsługi spraw może to być identyfikator sprawy, analizując obieg faktur – numer faktury
- stempel czasowy określający czas rozpoczęcia lub zakończenia aktywności
- nazwę aktywności/zadania
Na dużo większe możliwości późniejszej analizy pozwala zestaw danych obejmujący tak stempel czasowy rozpoczęcia jak i zakończenia zadania.
W ramach wprowadzenia przeanalizujmy bardzo prosty zestaw danych składający się z zdarzeń zarejestrowanych dla jednej sprawy. W kontekście każdego zdarzenia podana jest data i czas rozpoczęcia i zakończenia. Wynikiem ich przetworzenia przez algorytm PM jest model przedstawiony na rysunku poniżej. Zawiera on również prostą wizualizacje wolumetrii tego procesu, tj. informację ile spraw przechodziło między zadaniami i inicjowało zadania.
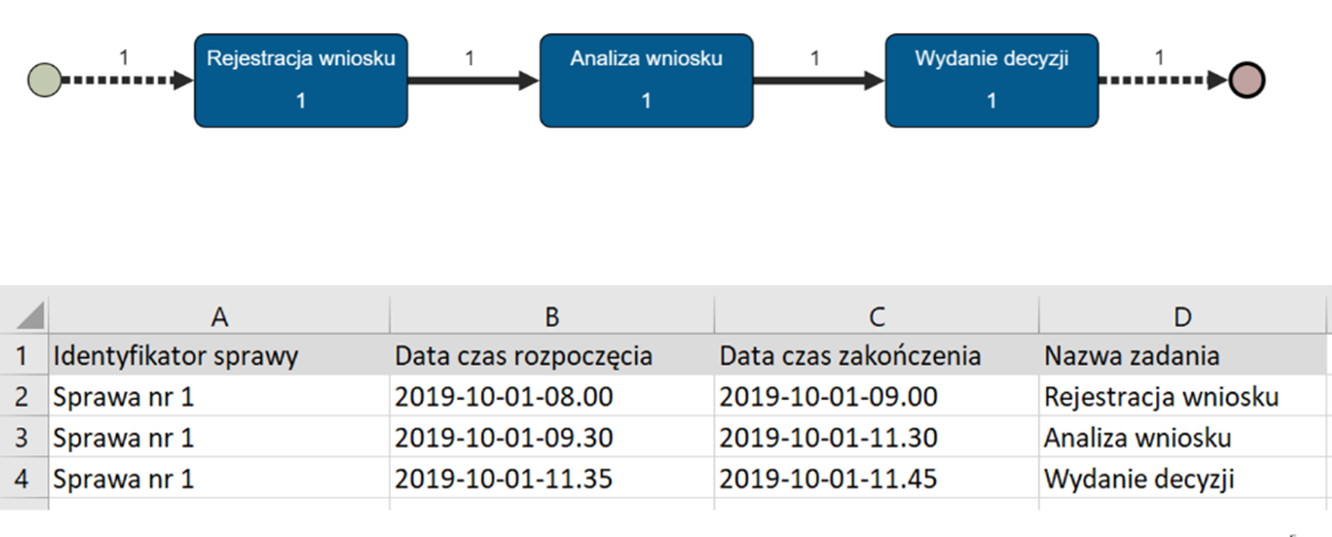
Rysunek 2 Prosty model z wizualizacją ilościową. Źródło: Opracowanie własne
Możliwa jest również analiza czasów realizacji poszczególnych zadań i/lub czasów przejść między nimi. Zaprezentowano to na rysunku poniżej.
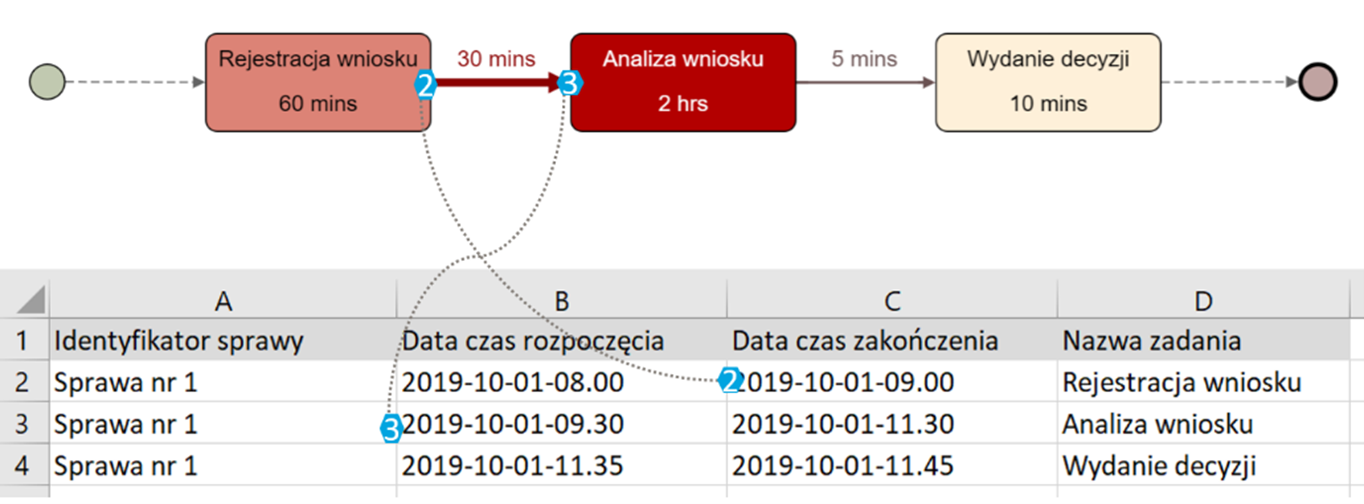
Rysunek 3 Prosty model z wizualizacją czasów. Źródło: Opracowanie własne
Analizę czasów możemy przeprowadzić także w przypadku gdy nie jest dostępny jednocześnie stempel czasowy dla rozpoczęcia i zakończenia zadania. Wystarczy tylko jeden z nich, choć oczywiście będzie się to wiązać z pewnymi ograniczeniami i uproszczeniami.
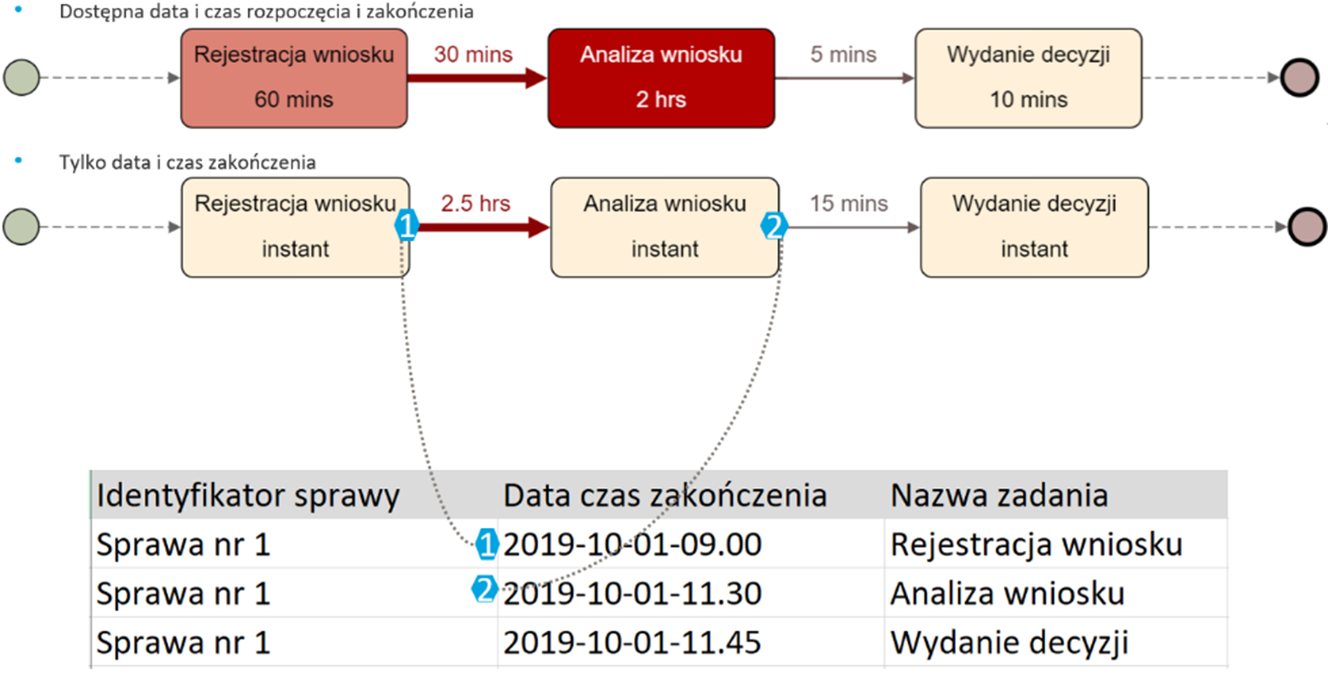
Rysunek 4 Uproszczenia i ograniczenia w wizualizacji czasu w przypadku gdy dostępny jest tylko jeden stempel czasowy. Źródło: Opracowanie własne
Na rysunku 5 przedstawiono model procesu biznesowego wytworzony w narzędziu Apromore. Dostępne są wskaźniki opisujące podstawowe charakterystyki procesu. Oprócz opisanych wcześniej KPI ilościowych i czasowych podany jest również wskaźnik Case Variants (Liczba wariantów procesu). Jest to liczba unikalnych ścieżek przejścia procesu ustalona w oparciu o log. W podanym przykładzie jest ona równa 1 z uwagi na fakt iż w logu znajduje się tylko jedna sprawa.
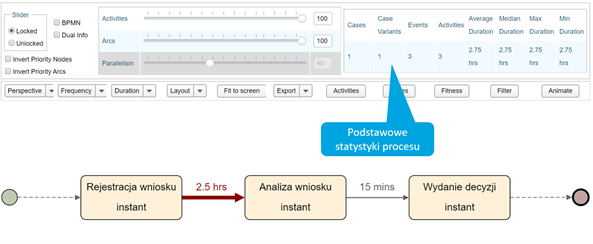
Rysunek 5 Wizualizacja modelu procesu i jego podstawowych statystyk w narzędziu Apromore (20st)
Dane w logu zdarzeń wykorzystywanym w PM mogą też posiadać dodatkowe informacje takie jak:
- Nazwa i rola podmiotu realizującego dany krok/zadanie.
- Jego rodzaj – człowiek czy system.
- Jednostka organizacyjna w której jest wykonywany dany krok procesu.
- Inne pomocnicze dotyczące np. kosztu czy tez dowolne informacje charakteryzujące daną sprawę w obrębie procesu.
Korzystając z nich, algorytmy Process Mining są w stanie wygenerować model danego procesu biznesowego, uzupełniając go o wolumetrie pozwalającą na ocenę procesu oraz jego późniejsze usprawnianie. Przykład takiego podejścia zaprezentowano na rysunku 6.
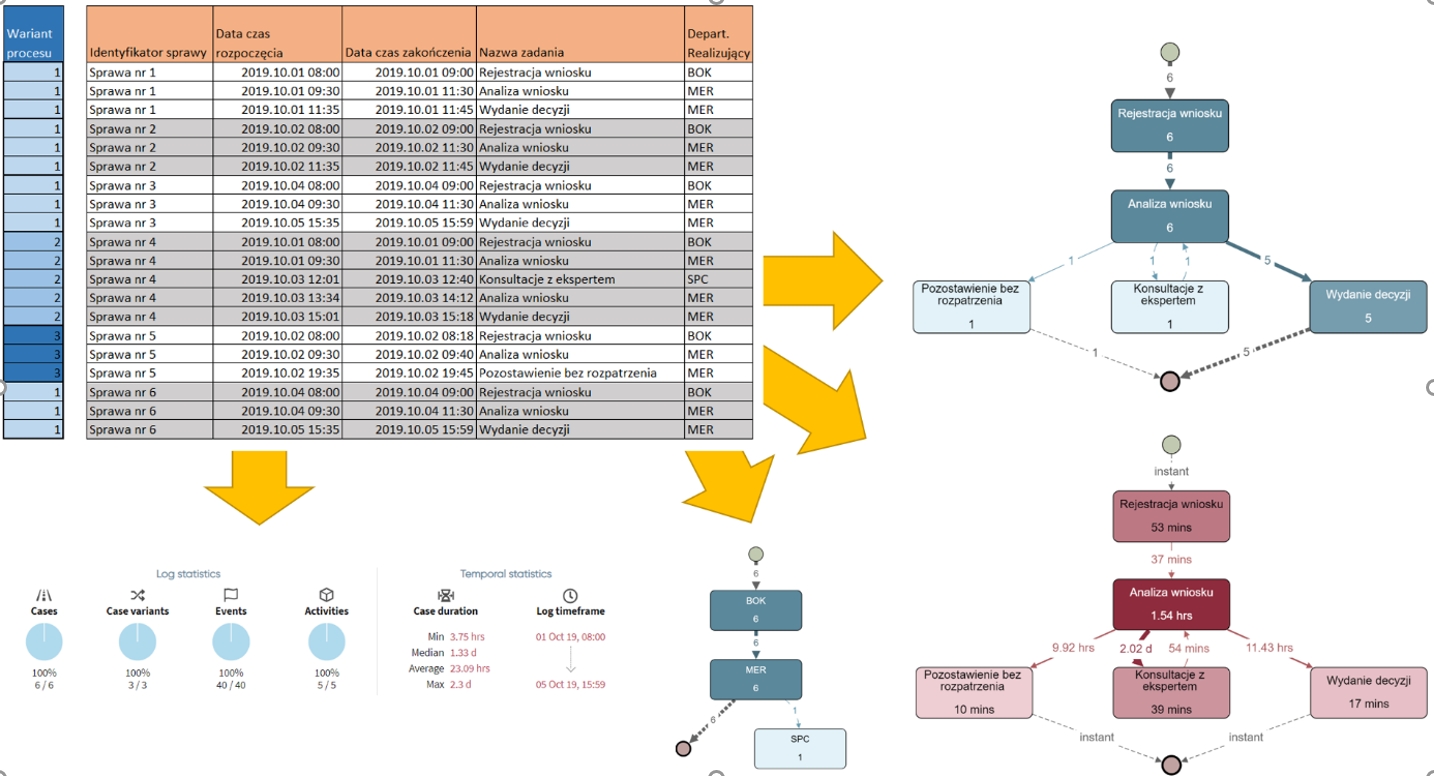
Rysunek 6 Process Mining wykorzystując dane z logu pozwala na odkrywanie procesów, ich monitorowanie i usprawnianie
Wykorzystano dane zawierające informację o krokach procesu w kontekście 6 spraw. Dane pochodzą z okresu 1-5 października 2019 roku. Obserwowany proces jest realizowany w kontekście 3 wariantów procesu, przy czym wariant 1 to aż 4 z 6 zarejestrowanych przebiegów. Najczęściej wykonywane kroki procesu to „Rejestracja wniosku” i „Analiza wniosku”. Najdłuższy średni czas realizacji ma krok „Analiza wniosku” – 1.54 godziny, a najdłuższy czas oczekiwania na realizację kroku – 2.02 dnia, występuje przy przejściu z kroku „Analiza wniosku” do „Konsultacje z ekspertem”. Są to potencjalne obszary do usprawnień. W realizacji tego procesu uczestniczą trzy departamenty: BOK,SEC i SPC. Możliwa jest wizualizacja obiegu spraw pomiędzy nimi.
Process Mining to metodyka, która pozwala na pozyskanie rzeczywistego obrazu przebiegów badanych procesów , na podstawie danych z systemów informatycznych przedsiębiorstwa. Można ją porównać do „rentgena”, który pozwala na uchwycenie tego, co się dzieje wewnętrznych procesach firmy.
Potencjalne korzyści z stosowania Process Mining to:
- Odkrywanie procesów — w wyniku przetworzenia algorytmami PM danych o zdarzeniach, otrzymujemy model procesu.
- Identyfikacja “wąskich gardeł” procesu – dzięki mierzeniu czasów i krotności przejść między poszczególnymi krokami oraz czasu i krotności wykonania danego zdarzenia.
- Ocena stopnia standaryzacji – poprzez porównanie liczby wariantów procesów do ogólnej liczby badanych przebiegów. Przyjmuje się że w ustandaryzowanym procesie kilka najczęstszych wariantów procesu powinna obejmować większość badanych przebiegów procesu. Im bardziej ustandaryzowany proces tym bardziej podatny jest on na późniejszą automatyzację.
- Weryfikacja zgodności procesu z obowiązującymi standardami — badamy różnicę miedzy modelem procesu „to be” a modelem wytworzonym w oparciu o rzeczywiste dane. Dzięki temu możliwe jest wychwycenie niezgodności i podjęcie ewentualnych działań naprawczych.
