Kubernetes dla .NET Developerów w przykładach dla .NET Core – część 1

Trudno wyobrazić sobie współczesny świat mikroserwisów bez istnienia kontenerów. Pierwszym rozwiązaniem, który wykreował współczesny kształt kontenerów jest Docker.
Historia i opis czym jest Docker
Projekt Docker został zaprezentowany w roku 2013 na konferencji związanej z Pythonem PyCon. Pierwotnie został wydany jako open-source i bazował na środowisku wykonawczym kontenerów LXC. Był w zasadzie jego nakładką, która ułatwiała pracę z tym środowiskiem. We wczesnej wersji 0.9 uległo to zmianie i element LXC został zamieniony własną implementacją silnika konteneryzacji libcontainer. Następne lata przyniosły rozwinięcie i rozrost projektów bazujących na Dockerze. W pracę nad własnymi aplikacjami zaangażowały się takie firmy jak Redhat oraz wiele firm mających swoje rozwiązania chmurowe takie jak Google (Google Cloud), Microsoft (Azure) czy Amazon (AWS). W roku 2021 została zmieniona licencja dla Docker Desktop i przestał być darmowy dla użytkowników komercyjnych.
Opis samego Dockera powinniśmy zacząć od podania definicji kontenera. Kontenerem nazywamy rodzaj wirtualizacji, która umieszczona jest na poziomie systemu operacyjnego. Ten sposób wirtualizacji czyli konteneryzacja zakładała, że jądro systemu jest wspólne. Wirtualny i umieszczony w kontenerze jest tylko system operacyjny oraz jego system plików. Jest to z założenia tak zwana lekka wirtualizacja, bo nie wymaga tak dużego nakładu sprzętowego bo mamy pewną część wspólną wielu kontenerów.
W celu dokładnego omówienia sposobu działania Dockera spójrzmy na poniższy schemat.
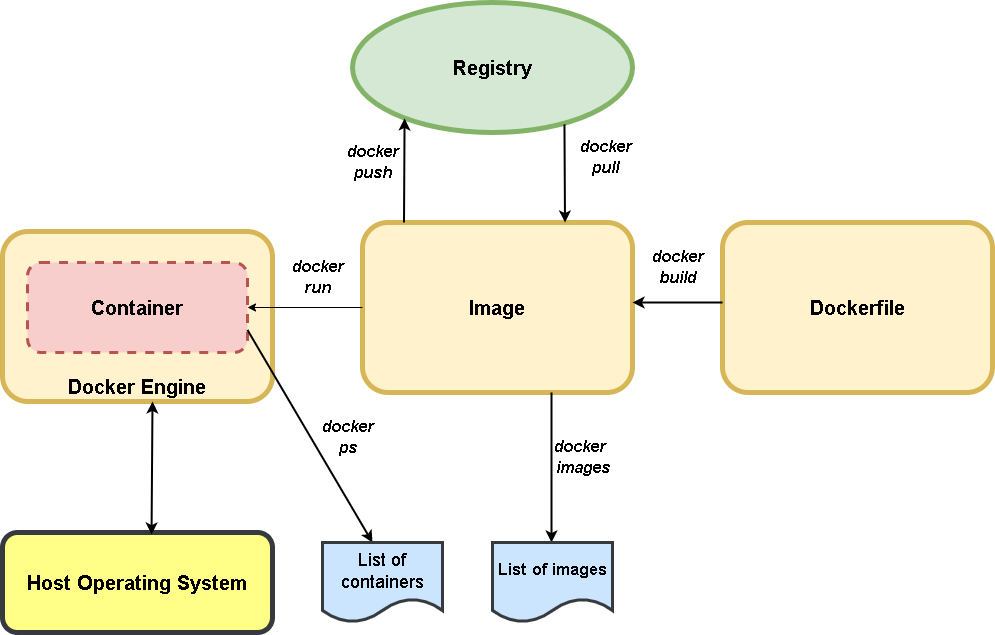
Źródło: Rysunek 1. Materiał własny autora.
Zacznijmy od prawej strony rysunku. Wdrożenie własnego obrazu(image) w postaci kontenera (container) powinniśmy zacząć od napisania pliku opisującego taki obraz (image), czyli Dockerfile. W pliku tym zawieramy instrukcje, które umożliwiają utworzenie takiego obrazu. Plik Dockerfile powinien rozpocząć się od instrukcji FROM, który mówi jaki inny obraz będziemy rozwijać i rozszerzać. Dla wielu dystrybucji Linux mamy przygotowane takie obrazy bazowe. Następnie by przygotować obraz dla Dockera uruchamiamy instrukcje docker build by taki obraz zbudować.
Powstanie wtedy fizycznie nasz zdefiniowany obraz, którego możemy potem użyć do wdrożenia jako kontener. W skrócie obraz jest to szablon nowego systemu operacyjnego wraz ze zmianami, które wprowadzimy w Dockerfile by wdrożyć naszą aplikacje. Tak utworzony obraz będzie zapisany na naszej lokalnej instalacji Dockera.
Możemy go również umieścić na serwerze repozytorium za pomocą komendy docker push lub ściągnąć go z naszego repozytorium komendą docker pull.
Dla Dockera przygotowane zostało domyślne repozytorium, gdzie odnajdziemy wiele przygotowanych przez społeczność oraz samego producenta Dockera obrazów. Tym miejscem jest Docker Hub https://hub.docker.com/.
Przygotowany obraz możemy wdrożyć jako kontener. Służy do tego komenda docker run. Możemy także w każdej chwili zobaczyć listę obrazów, za pomocą komendy docker images oraz wyświetlić listę wdrożonych kontenerów komendą docker ps
Historia i opis czym jest Kubernetes
Docker zakładał, że wszystko dzieje się na jednej fizycznie maszynie (host) i jej systemie operacyjnym. W celu zbudowania skalowalnego rozwiązania i spełniającego zasadę wysokiej dostępności (HA) należało to rozwiązanie rozproszyć pomiędzy fizyczne maszyny. Ponadto trzeba było zbudować mechanizm zarządzania tak zbudowanym rozwiązaniem (klastrem) czyli zadbać o orkiestrację takich maszyn. W tym celu powstało nowe rozwiązanie Kubernetes, które miało na celu rozwiązanie tak postawionego problemu biznesowego.
Projekt Kubernetes (k8s) powstał w roku 2014 w firmie Google. Oficjalnie pierwsze wydanie wersji nastąpiło w roku 2015 i jest on licencjonowany na zasadach open-source. W chwili obecnej jest to najbardziej powszechnie używany mechanizm orkiestracji kontenerów. Na jego podbudowie powstało też klika projektów komercyjnych, które rozwijają koncepcje w nim zawarte np. Open Shift firmy Redhat.
W celu lepszego zrozumienia jak działa Kubernetes dokonamy analizy poniższego schematu.
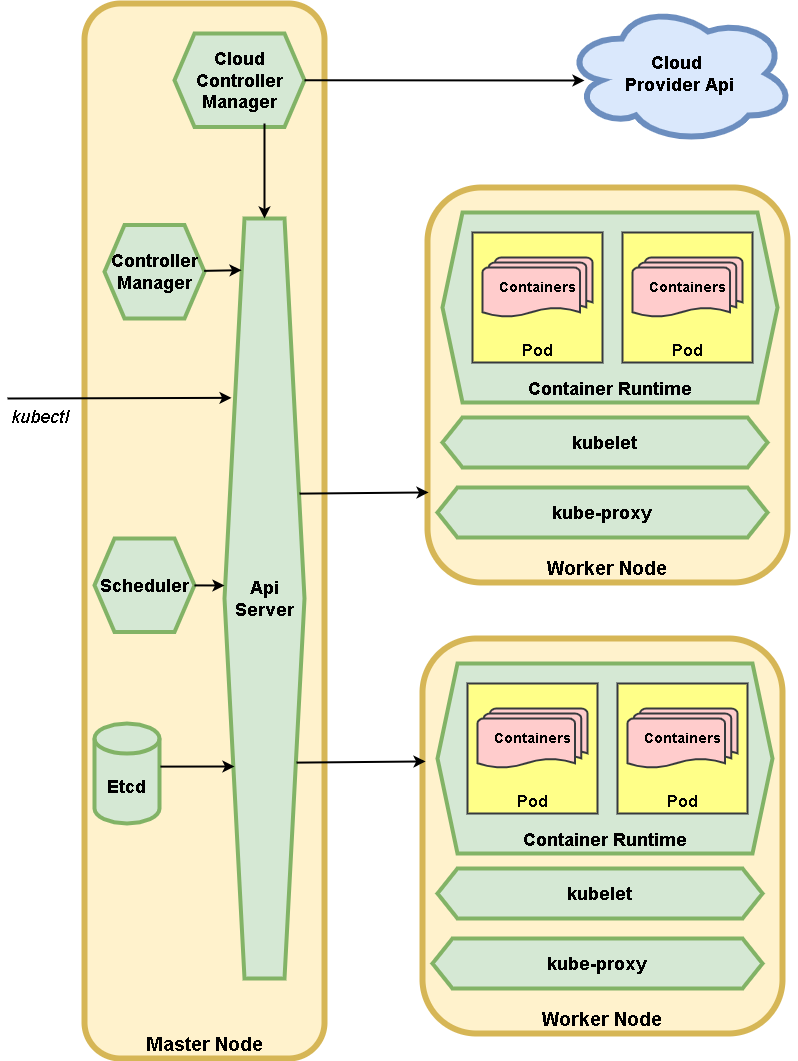
Źródło: Rysunek 2. Materiał własny autora.
Zacznijmy od składowych komponentów i wyjaśnijmy ich rolę w tym schemacie:
- Worker Node – węzeł odpowiedzialny za pracę w klastrze. Możemy utożsamiać go z jedną fizyczną lub wirtualną maszyną.
- Master Node – węzeł odpowiedzialny za kierowanie pracą w klastrze. Możemy taki node utożsamiać z jedną fizyczną lub wirtualną maszyną.
- Cloud Provider API – API wystawione przez twórcę chmury za pomocą , którego możemy zintegrować nasz klaster z rozwiązaniem chmurowym
Na worker node możemy wyróżnić następujące komponenty:
- kube-proxy – odpowiedzialny za przekierowane ruchu sieciowego do odpowiedniego poda
- kubelet – serwis sterujący pracą jednego węzła
- Container Runtime – środowisko uruchomieniowe dla kontenerów. Uruchamia odpowiednie pody oraz zawarte w nich kontenery (pierwotnie ta rolę pełnił docker)
Na master node możemy wyróżnić następujące elementy
- API Server – końcówka komunikacji z innymi serwisami oraz wystawia API do sterowania tą pracą z zewnątrz klastra
- Etcd - baza na, której zapisywany jest stan oraz ustawienia klastra
- Scheduler – serwis odpowiedzialny za wykonanie zleconych zadań dla klastra
- Controller Manager – główny serwis sterujący pracą klastra
- Controller Cluster Manager – serwis służący do integracji klastra z rozwiązaniami chmurowymi
Do sterowania pracą klastra Kubernetesa używamy polecenia kubectl. Program ten łączy się bezpośrednio z API Server.
Na zakończenie zróbmy pewne podsumowanie. Świat tworzenia oprogramowania ulega ciągłej zmianie. By można było stosować nowe wzorce takie jak mikroserwisy potrzebujemy odpowiednich narzędzi do ich wdrażania. Jako rozwiązanie tak sformułowanej potrzeby biznesowej powstał Docker a potem jego idee rozwinął Kubernetes.
W następnej części pokażemy jak postawić prosty klaster Kubernetesa wielo-węzłowy na naszej maszynie lokalnej. Użyjemy w tym celu pełnej wirtualizacji opartej o Oracle Virtualbox oraz oprogramowania Vagrant. Wykonamy także pierwszą aplikacje w .NET Core i wdrożymy ją na naszym klastrze.
