Monorepo czy multirepo w złożonym projekcie programistycznym?

No i zaczyna się, przychodzi klient i zamawia projekt. Nastaje euforia, drobny rachunek sumienia z poprzednich realizacji i teraz wszystko zrobimy po nowemu, lepiej, wydajniej i szybciej. Nowiuśkie technologie, najnowsze frameworki, koniecznie docker i kubernetes, może jakiś serverless i oczywiście mikroserwisy, angular albo nawet vuejs. W całej tej euforii pojawia się sporo pytań odnośnie kształtu i realizacji projektu. Jedno z nich to, czy skoro będziemy mieli nową bazę kodu, zapewne z wieloma „niezależnymi” modułami, to czy warto ją rozbić na wiele mniejszych repozytoriów, czy może przechowywać wszystko w jednym wielki hiper-repozytorium?
Pierwsza odpowiedź, jaka nam przychodzi do głowy to oczywiście zróbmy wiele mniejszych repozytoriów dla każdego wydzielonego modułu, aby łatwiej zarządzać kodem i wprowadzać autonomię tak jak to radzą w książce albo na konferencji. Niestety poprawna odpowiedź nie jest tak trywialna i kompletnie nie zależy od tego, co w obecnej chwili jest modne w programistycznym świecie. Poprawną odpowiedzią jest nieśmiertelne już w IT: „To zależy”.

Rysunek 1 Mono Repo vs Multi-Repo
W zasadzie tutaj można by postawić kropkę i wystawić fakturę będąc początkującym architektem, czy senior developerem. My natomiast zastanówmy się nad tym, które rozwiązanie jest lepsze i w jakim kontekście. Skoro w ogóle pojawił nam się wybór już na tak wczesnym etapie nowego projektu to znaczy, że podjęcie złej decyzji może nas sporo kosztować w dłuższej perspektywie. Wszystkie projekty, które stają się w jakiś magiczny i niespodziewany sposób kodem „legacy”, kiedyś były dobrze zapowiadającym się, nowoczesnymi kawałkami nieskalanego kodu, w których ktoś też popełnił kilka małych błędnych decyzji.
Monorepo
W podejściu monorepo mamy jedno wielkie repozytorium, nad którym pracują wszyscy zaangażowani w projekt programiści. Praca w takich warunkach w początkowej fazie projektu wymaga bardzo dużo dyscypliny i doświadczenia, gdyż każdy popełniony błąd może wpłynąć na pracę innych. Przemyślenie struktury katalogów, czy wybranie konwencji nazewniczych powinno być traktowane bardzo poważnie. Powinno być sformalizowane przez udokumentowanie reguł panujących w repozytorium chociażby w pliku README oraz egzekwowanie ich przy pomocy, czy to narzędzi do statycznej analizy kody czy po prostu weryfikacji wprowadzanych zmian przez mechanizm Pull-Requestów. Niestety nietrzymanie się zasad może powodować konflikty między zespołami próbującymi przejąć dominację.
Ważnym aspektem pracy z pojedynczym repozytorium jest konieczność związania się z jedną wybraną technologią, w której będzie powstawać cały projekt. Jeśli decydujemy się na .NET, Javę, czy Pythona to taka decyzja pozostanie z nami do końca projektu. Są oczywiście frameworki do tworzenia monorepo wielotechnologicznego takie jak Nx, który ma wsparcie dla frameworków javascript-owych, dotnet-a, a nawet java-owego Spring Boot-a, ale nie są to rozwiązania jakoś szczególnie popularne, a ich wykorzystanie wiąże się z ryzykiem błędów w działaniu i małym wsparciem ze strony społeczności.
Popularne narzędzia do kontroli wersji takie jak: SVN i GIT, dobrze radzą sobie z dużymi repozytoriami, chociaż jeszcze kilka lat temu kilkuset megabajtowe, czy gigabajtowe repozytoria mogły stanowić dla nich wyzwanie. Praca dużej liczby osób nad jednym repozytorium może powodować częstą potrzebę rozwiązywania konfliktów mergowania zmian. Z drugiej strony problem ten można wyeliminować wprowadzając konieczność wykonywania zmian na indywidualnych gałęziach i dołączania ich do gałęzi głównej przy pomocy pull requestów. Dzięki mechanizmowi pull requestów możemy nałożyć polityki weryfikujące dodawane zmiany, takie jak uruchomienie procesów Continous Integration (budowanie, testowanie, analiza statyczna kodu) dbających, aby główna gałąź zawsze zawierała w pełni poprawny i budujący się kod. Możemy nałożyć politykę wymagającą zatwierdzenia dodawanych zmian przez recenzentów.
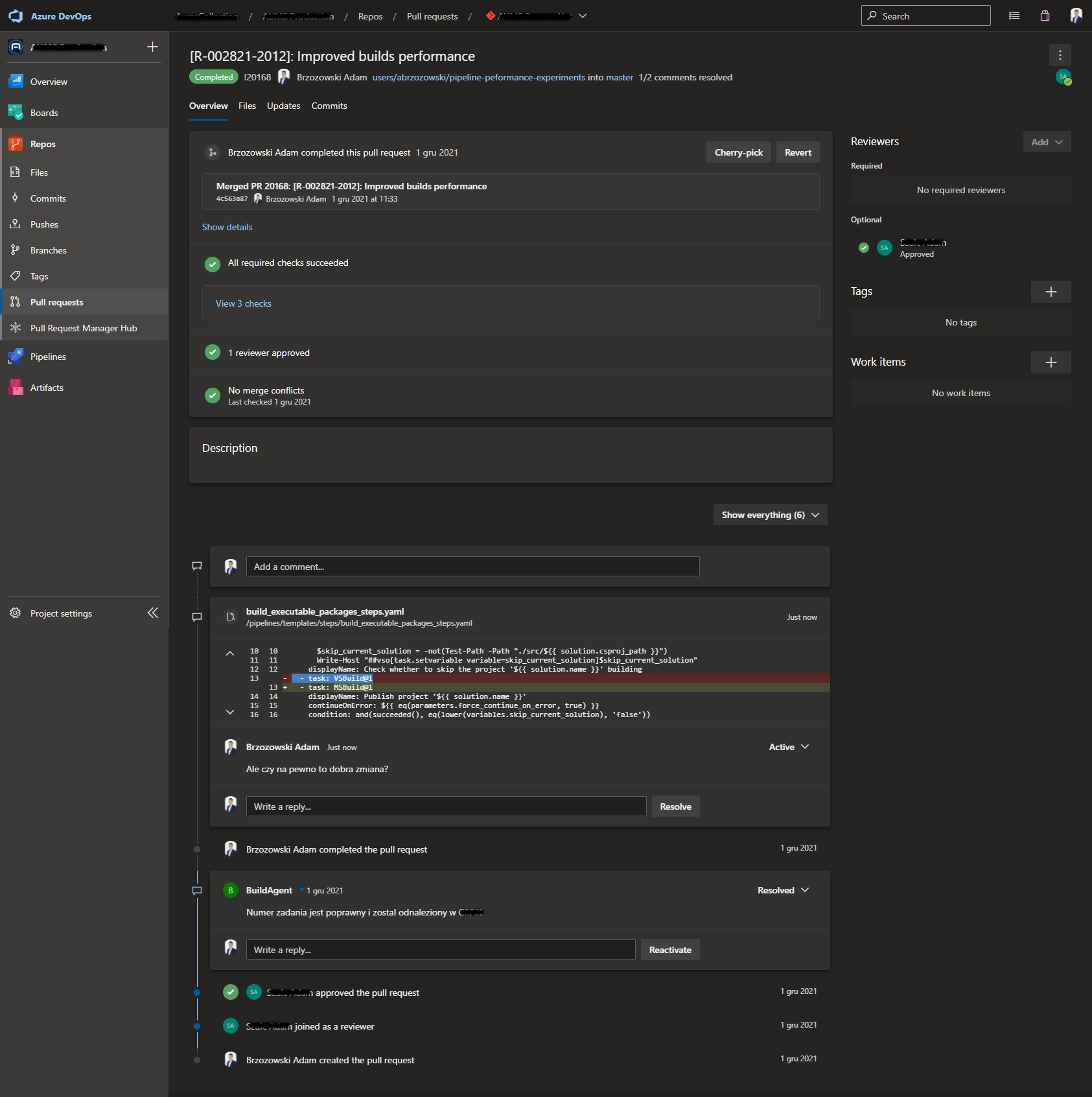
Rysunek 2 Przykładowy Pull-Request w Azure DevOps
Dodatkową zaletą centralnego repozytorium jest łatwiejsze wprowadzanie nowych programistów w projektu. Nie muszą oni przeszukiwać różnych repozytoriów eksplorując system, a mają wszystko w jednym miejscu.
Monorepozytorium świetnie sprawdza się w pracy z małymi zgranymi ze sobą zespołami lub wręcz w pracy tylko jednego zespołu. Wtedy naturalnie nie odczuwamy problemów i konfliktów między ludzkich, a do tego możemy zyskać większy przyrost nowych funkcjonalności w początkowej fazie projektu dzięki oszczędzeniu czasu na projektowanie i wdrażanie narzędzi do panowania na mnogością repozytoriów.
Monorepo w podejściu serwisowym
Czy to w architekturze service oriented architecture (SOA), czy mikroserwisach ważne jest, aby poszczególne serwisy był od siebie niezależne i nie współdzieliły kodu, a jedynie komunikowały się ze sobą poprzez ustalone kontrakty. Niestety trzymając kod wielu serwisów w jednym ogromnym repozytorium bardzo często sprzyja uchybieniom i dodawaniu referencji między modułami które nigdy nie powinny występować. Referowanie modułu z klasą użytkownika i wszystkimi funkcjami do obsługi użytkowników z serwisu „user” w serwisie „articles”, tylko dlatego, że potrzebujemy użyć jednej klasy jest bardzo złą praktyką. Ogromna ilość zależności między modułami w monorepo spowalnia budowanie całej solucji, ponieważ uniemożliwia równoległe budowanie poszczególnych serwisów. Dodatkowo mikroserwisy tracą niezależność i autonomię czyli fundamenty tej architektury, jeśli są ze sobą splątane zależnościami.
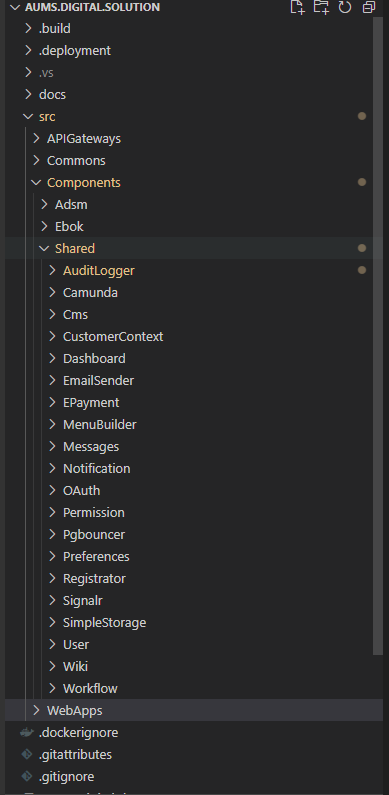
Rysunek 3 Struktura przykładowego projektu mikroserwisowego w monorepo
Pojedyncze repozytorium w aplikacji mikroserwisowej daje korzyści w postaci mniejszego nakładu pracy na infrastrukturę programistyczną i technologię. Nie potrzebujemy serwera pakietów współdzielonych (commons-ów, utils-ów, shared-ów, itp.), gdyż z racji posiadania całego kodu w jednym repozytorium, wystarczą referencje między projektami. Łatwiej jest przechowywać elementy wspólne takie jak szablony helm, skrypty, szablony pipeline-ów albo dokumentację projektu. W monorepo o wiele łatwiej jest refaktoryzować kod, mając wsparcie ze strony IDE na całym projekcie. Wszelkie większe operacje takie jak podniesienie wersji używanego frameworka lub zmiana jakiegoś komponentu są o wiele łatwiejsze i szybsze do wykonania w monorepo.
Częstym zarzutem do zaprzestania korzystania z monorepo w kontekście mikroserwisów jest utrudnione niezależne wydawanie serwisów. Na szczęście nie jest to przeszkodą, gdyż z pomocą przychodzą nam nowoczesne narzędzia CI&CD takie jak Azure DevOps, które umożliwiają uruchamianie poszczególnych pipeline-ów w zależności od folderów, w których dokonano zmian.
Monorepo dla aplikacji frontendowych
Trochę inaczej ma się sytuacja przy aplikacjach frontendowych dla których koncepcja monorepo jest bliższa. Mając do dyspozycji frameworki takie jak Nx można w łatwy i ustandaryzowany sposób przechowywać w obrębie jednego repozytorium wiele niezależnych aplikacji używanych w przedsiębiorstwie i wykorzystywać komponenty, czy biblioteki pomiędzy nimi. Wytwarzanie aplikacji frontendowych SPA w dużej mierze opiera się na składaniu formatek z komponentów, które mogą składać się z kolejnych komponentów. Przy takim podejściu trzymanie każdej aplikacji w osobnym repozytorium wymaga dystrybuowania komponentów współdzielonych przez npm-a i uniemożliwia szybki podgląd wprowadzanych zmian w przeglądarce.
Multirepo
W podejściu multirepo mamy wiele niezależnych repozytoriów z powydzielanymi modułami (zwykle serwisami) tworzących razem cały projekt. Początek takiego projektu okupiony jest zwykle pewnym chaosem, gdyż każdy zespół lub programista może rozpocząć pracę nad swoją częścią bez konieczności oczekiwania na wypracowanie standardów czy ustalenie globalnie używanych technologii. W każdym repozytorium należącym do multi repo mogą panować odmienne zasady i standardy, a nawet mogą być wykorzystywane zupełnie odmienne technologie, co oczywiście jest ogromną zaletą i idealnie sprawdza się przy projekcie który będzie realizowany przez wiele zespołów, bo od samego początku pozwala programistą szybko i niezależnie realizować swoje zadania. Każdy zespół pracujący nad swoimi repozytoriami dostaje jakąś formę autonomii i może skupić się na doszlifowaniu swojego warsztatu i ustaleniu własnych panujących wewnętrznie zasad.
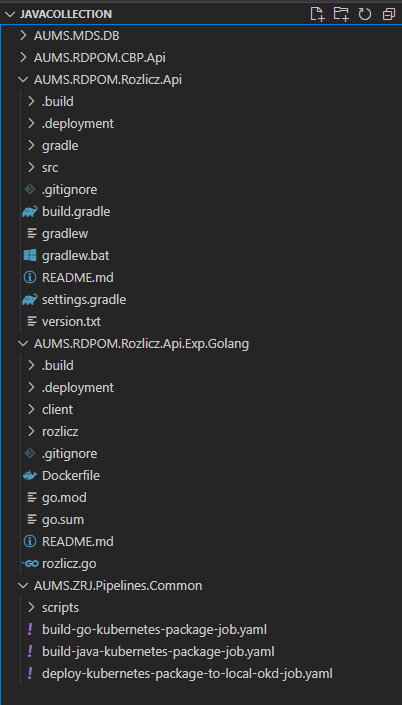
Rysunek 4 Przykładowy projekt multi-repo z wydzielonymi szablonami pipeline-ów do osobnego projektu i przykładem jednej usługi napisanej w 2 różnych technologiach (Java i Go) w ramach eksperymentu
Oczywiście większe schody zaczynają się na etapie integracji modułów ze sobą, czy też wdrożenia na pierwsze środowiska całej aplikacji. Jeśli każde repozytorium zawiera moduły napisane w oddzielnych technologiach, to zwiększa się prawdopodobieństwo napotkania problemów wynikających z niuansów różniących te technologie. Czasami różne technologie nie obsługują tych samych standardów szyfrowania lub nie implementują w pełni wszystkich funkcji z protokołu (np. gRPC). Przez to możemy poczuć się jak budowniczy którzy rozpoczęli budowę mostu po obu stronach rzeki, a przy finiszu prac, punkt ich łączenia nie zbiega się w tym samym miejscu. Oczywiście nie ma sytuacji bez wyjścia i naturalnie takie problemy idzie wyeliminować, ale wymaga to pewnego nakładu pracy.

Podział modułów na wiele repozytoriów zabezpiecza programistów przed popełnianiem błędu referowania modułów i bibliotek między modułami, które nie powinny mieć ze sobą powiązań. Wymuszenie jawnego wydzielenia części wspólnych (commons-ów, utils-ów, czy klas DTO) musi być zamierzonym i przemyślanym działaniem. Oczywiście nie chroni to projektu w pełni przed błędami zacierania granic serwisów, albo zwiększania niechcianego couplingu.
W realizacji projektu w realiach branży IT często jesteśmy narażeni na ubogie zasoby ludzkie lub zwyczajne zmiany kadrowe. Przy podejściu multirepo i autonomii panującej w każdym repozytorium przełączanie się programistów między zespołami, aby wspomóc się wzajemnie nie jest takie łatwe, gdyż może wymagać podobnego wdrożenia w zasady panujące w danym zespole do zatrudnienia całkiem nowego pracownika. Czy ten argument jest dla nas ważny? Zależy od poziomu umiejętności programistów w naszych zespołach. Migracja między zespołami będzie łatwiejsza dla doświadczonego seniora niż dla młodego i ambitnego juniora.
Czy można zmienić decyzję w połowie trwania przedsięwzięcia?
Decyzja monorepo czy multi-repo, mimo że musi zostać podjęta na bardzo wczesnym etapie, nie jest nieodwracalna. Może się okazać, że zespoły pracujące w danej metodologii zwyczajnie dojrzewają do decyzji zmiany podejścia podyktowanej zmieniającą się sytuacji w projekcie.
Zwykle kierunek rozwoju jest taki, że rozbijamy w nieinwazyjny sposób monorepo do multi-repo, nie wstrzymując bieżących prac. Jest to zadanie dosyć łatwe, o ile mieliśmy na początku jasno ustalone reguły pracy w projekcie. Jeśli moduły (serwisy) znajdujące się w repozytorium nie są ze sobą ściśle powiązane i przestrzegaliśmy zasad wybranej architektury mikroserwisów, SOA czy modularnego monolitu, to nic nie stoi na przeszkodzie, aby rozbić nasze monorepo na multi-repo.
Inaczej ma się sytuacja, gdy na starcie projektu mamy multi-repo. Rzadziej słyszy się wtedy o migrowaniu do monorepo, aczkolwiek nie jest to pomysł pozbawiony sensu. W początkowej fazie wytwarzania, gdy mamy kilka zespołów, praca w multirepo wydaje się wygodniejsza. Jeśli w dalszej fazie projektu, zmniejsza się liczba pracujących nad nim zespołów, oraz spada zapotrzebowanie na dodawanie nowych funkcji, a zwiększa się na jakość i refaktoryzację kodu, sensowne może się okazać połączenie kilkunastu repozytoriów w jedno. Oczywiście problemem zaczyna być skala. Jeśli mamy do czynienia z dziesiątkami czy nawet setkami serwisów to ciężko jest zaplanować i wykonać migrację do monorepo. Połączenie wielu repozytoriów z zachowaniem początkowej separacji i autonomii poszczególnych modułów ułatwia mniejszemu zespołowi utrzymanie i rozwój kodu stworzonego przez początkowy większy zespół.
Podsumowanie
Jak widać wybór miedzy mono repo, a multirepo zależy od wielu czynników miękkich jak i technicznych. Podejmując decyzję powinniśmy kierować się doświadczeniem zespołów, skalą przedsięwzięcia, dostępną technologią i narzędziami ją wspierającymi, a nie książkowym podejściem czy chwilową modą panującą w świecie IT. Znając mocne i słabe strony obu rozwiązań łatwiej będzie nam wybrać to, które lepiej pasuje do naszych potrzeb.
Decydując się na jedną z metodologii monorepo lub multi-repo, nie powinniśmy na siłę próbować tworzyć rozwiązań hybrydowych. Pojedyncze repozytorium agregujące wiele repozytoriów przy pomocy submodułów git-owych przysporzy nam wiele problemów. Monorepozytorium z wieloma solucjami i wybiórczo podłączonymi do nich projektami w relacji wiele do wielu też nie jest dobrym pomysłem. Półśrodki i wszelkie sprytne pomysły w tym obszarze prędzej czy później ukażą swoje ułomności i problemy, które w standardowych podejściach nie występują lub są wprost opisane i decydujemy się na nie z pełną tego świadomością.
