Spark dla .NET Developerów w przykładach dla .NET Core. Część 3

W poprzedniej części mojego wpisu napisaliśmy nasz pierwszy program w .NET Core na platformę Apache Spark. Pokazaliśmy jak uruchomić środowisko developerskie oraz omówiliśmy jak działa napisany przez nas kod. Teraz w ostatnim odcinku tej serii przybliżymy pracę interaktywną z Apache Spark dla platformy .NET.
Jak już wspominałem w pierwszym odcinku serii praca interaktywna z kodem to kluczowe ulepszenie jakie niósł Apache Spark w stosunku do Apache Hadoop.

Konfiguracja środowiska interaktywnego .NET for Apache Spark
Do konfiguracji środowiska developerskiego dla .NET for Apache Spark użyjemy narzędzia Docker. W tym celu użyjemy przygotowanego obrazu : hub.docker.com/r/3rdman/dotnet-spark
Interesował nas będzie jeden z wariantów tego obrazu czyli:
3rdman/dotnet-spark:interactive-latest
W celu uruchomienia tego obrazu uruchamiamy następująco komendę:
docker run --name dotnet-spark-interactive -d -p 8888:8888 3rdman/dotnet-spark:interactive-latest
Zauważmy, że przy uruchomieniu ujawniamy port 8888, który będzie nam służył do połączenie ze środowiskiem interaktywnym. Jak obraz zostanie uruchomiony musimy dowiedzieć się jaki adres url startowy ma środowisko JupyterLab w tym celu uruchamiamy komendę:
docker logs -f dotnet-spark-interactive
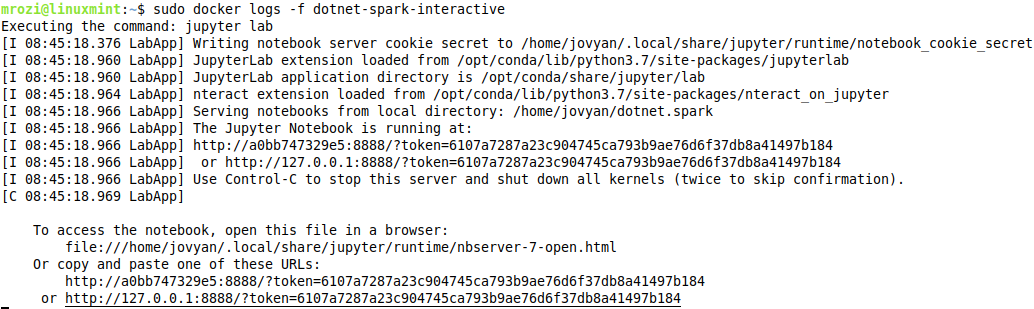
W przeglądarce uruchamiamy link zaczynający się adresem lokalnym 127.0.1. Na ekranie pojawi nam się okno startowe środowiska JupyterLab.
Tym samym nasze środowisko interaktywne jest już gotowe do pracy.
Praca z interaktywnym środowiskiem dla .NET for Apache Spark
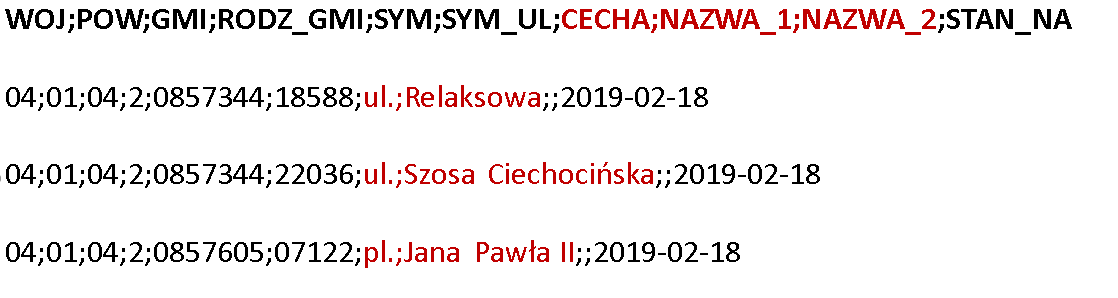
Naszym pierwszym programem , który napisaliśmy był ten określający najpopularniejszą nazwę ulicy w Polsce. Źródłem danych jest plik w formacie csv (plik streets.csv) którego strukturę widzimy na poniższym rysunku.
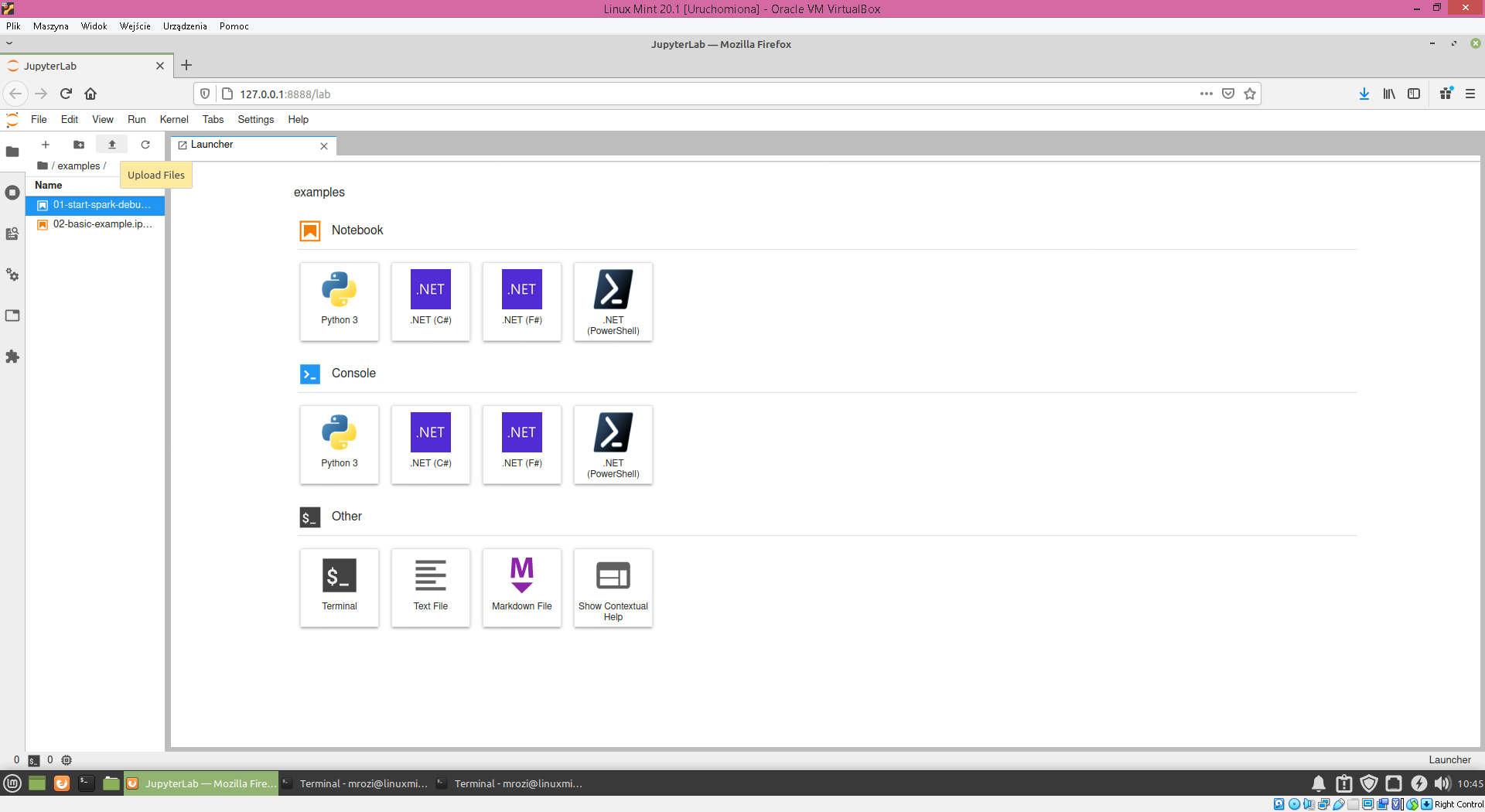
Plik ten musimy umieścić w naszym środowisku. W tym celu w katalogu examples wykonujemy polecenie upload files.
W repozytorium github.com/mrozim78/DotnetForApacheSparkExamples
W katalogu Notebooks odnajedziemy plik Streets.ipynb. Powinniśmy wgrać go tak samo jak poprzedni plik do katalogu examples.
W celu rozpoczęcia naszych operacji interaktywnych musimy najpierw uruchomić skrypt znajdujący się w pliku examples/01-start-spark-debug.ipynb. Przygotuje on oraz uruchomi nam nasze środowisko .NET w trybie debug . Po tej operacji możemy uruchomić interaktywnie nasz skrypt Streets.ipynb.
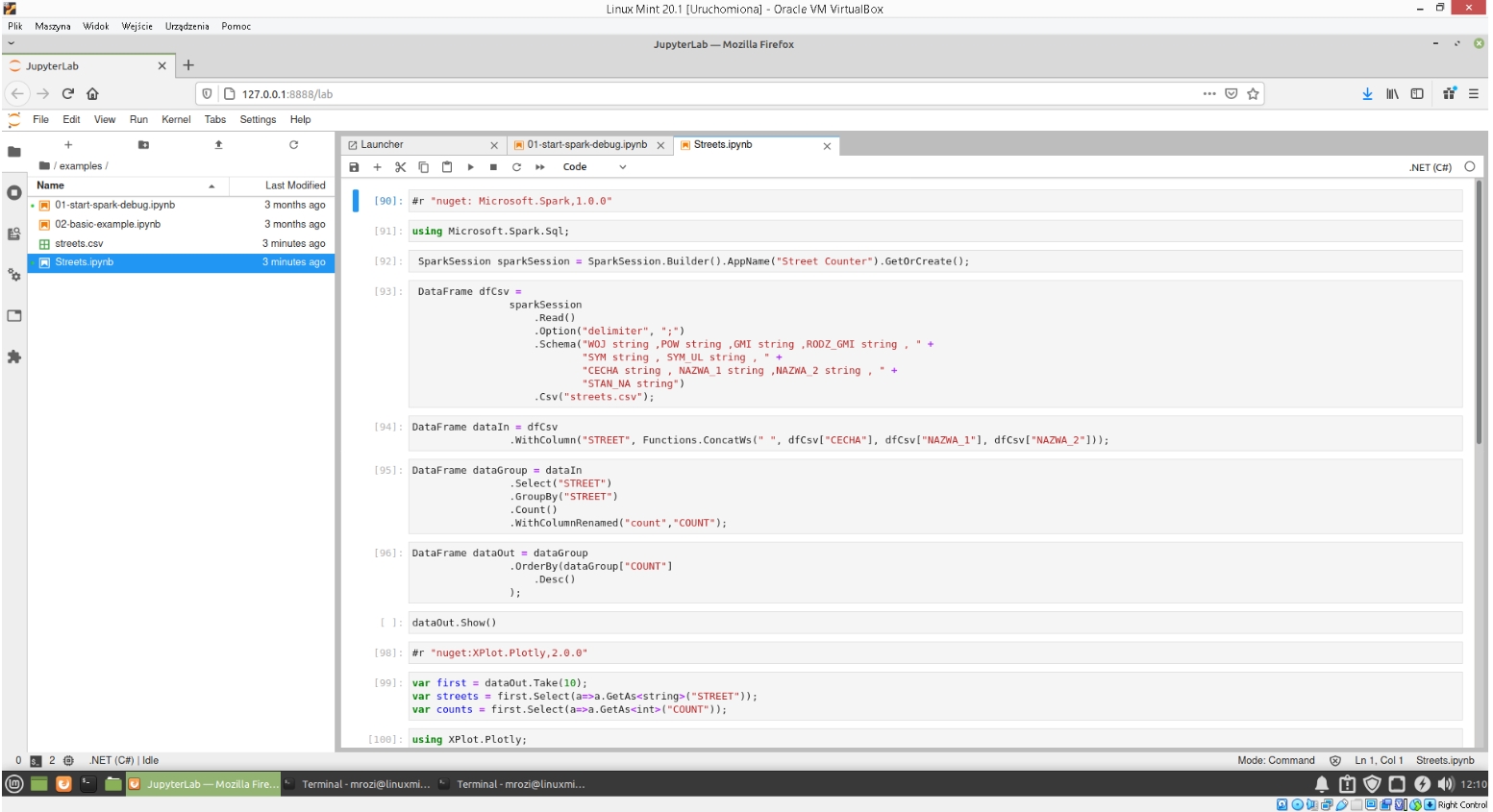
Zobaczmy co ten plik zawiera i omówmy jego działanie w kilku słowach.
Pierwsze polecenie z dyrektywą #r oznacza instalację potrzebnego pakietu nugetowego. Kolejne polecenia są takie same jak w programie napisanym w drugiej części naszego wpisu i do którego was odsyłam celu zapoznania się z dokładną analizą tego kodu. Analizując ten kod pobieżnie możemy zauważyć , że otwieramy w nim sesje Apache Spark oraz plik csv. Wykonujemy odpowiednie grupowania oraz agregujemy kolumny i liczymy ulicę o największej liczbie wystąpień. Wynik naszego działania znajduje się w DataFrame o nazwie dataOut. Potem następuje komenda show , która wyświetli nam częściowe dane z tego DataFrame (dokładnie 20 największych wystąpień dla ulicy).
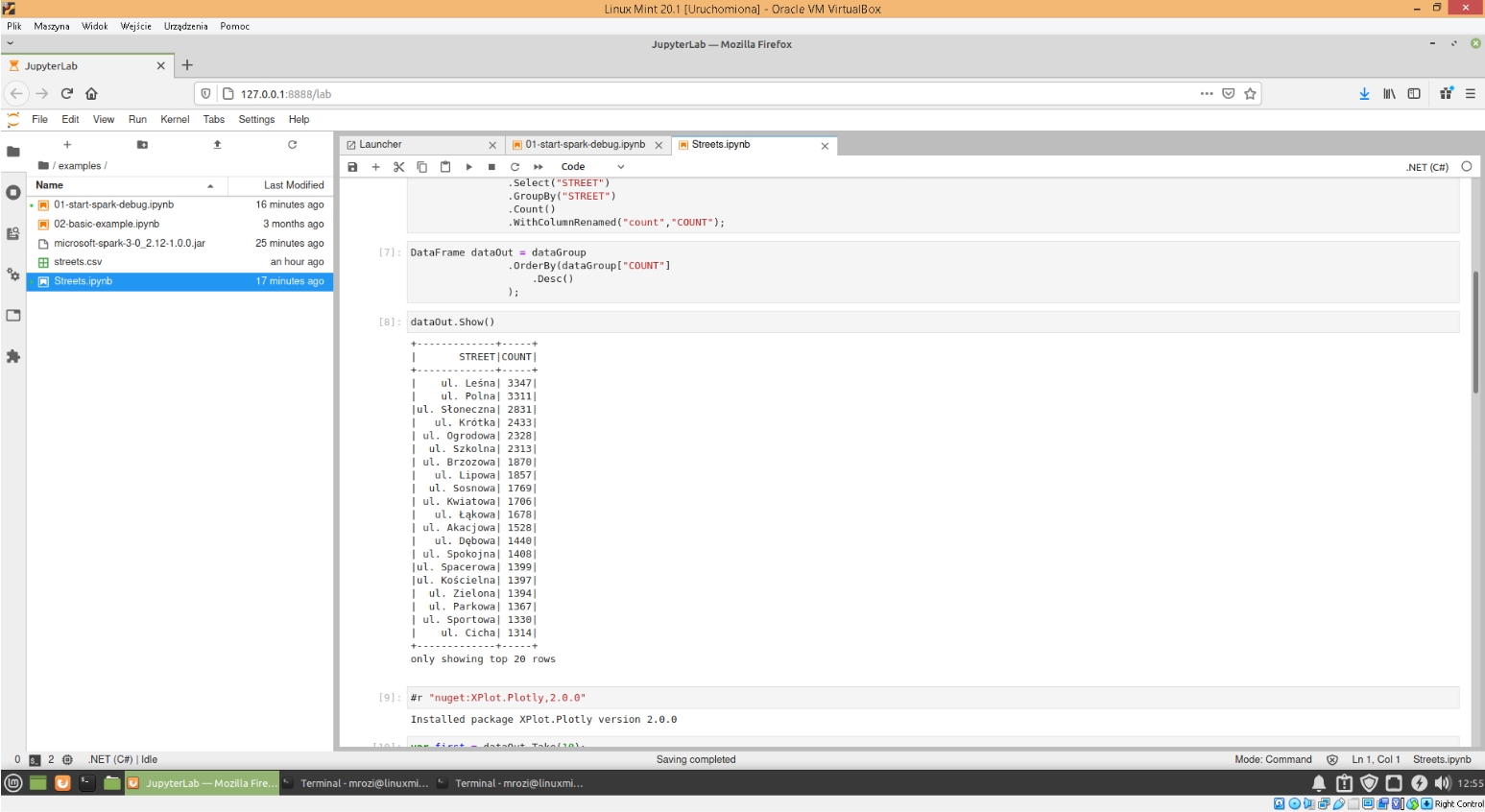
Użycie JupyterLabs nie tylko daje możliwość uruchomienia skryptu interaktywnie ale także możliwa jest inna analiza danych na przykład poprzez wykonanie odpowiednich wykresów. Przykład tego możemy zauważyć w naszym skrypcie. Na początku instalujemy odpowiedni pakiet nugetowy do wykresów o nazwie Xplot i nasze dane przekształcamy do formy , którą możemy zastosować w wykresach . Wyciągamy 10 największych wystąpień z DataFrame o nazwie dataOut i przekształcamy te dane w dwie listy , które zawierają nazwy ulic zmienna streets oraz ilość ich wystąpień zmienna counts
Następnie na podstawie tych danych rysujemy dwa wykresy: słupkowy oraz kołowy.
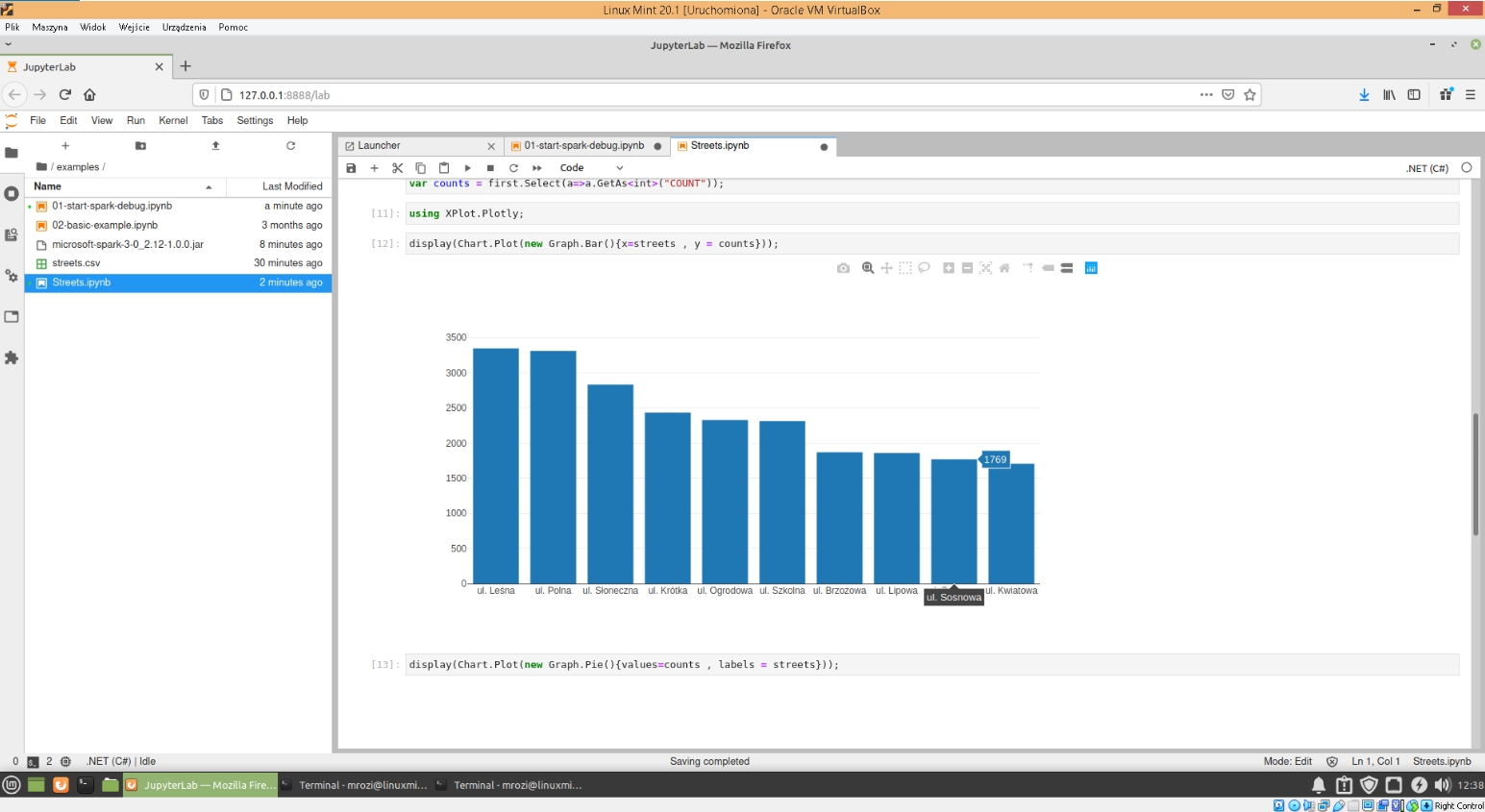
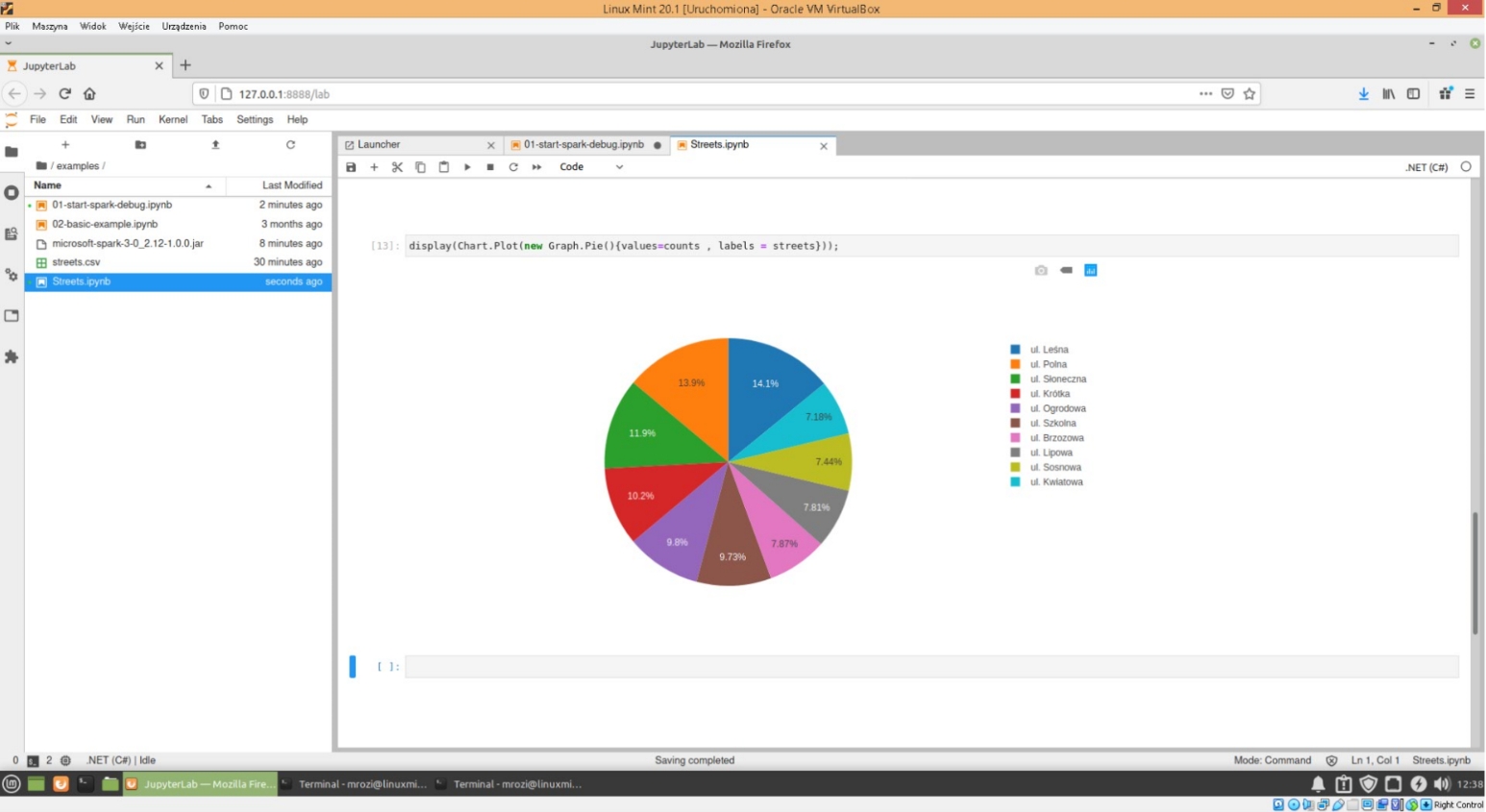
Pakiet Xplot umożliwia także wykonanie innego rodzaju wykresów ale z tym odsyłam was do dokumentacji tego pakietu.
W ten sposób dotarliśmy do końca naszej serii o Apache Spark dla .NET Core. Podsumowując możemy zauważyć , że praca z Apache Spark w języku .NET Core jest bardzo prosta i intuicyjna. Prace konfiguracyjne środowiska bardzo ułatwia nam narzędzie Docker. Użycie interaktywnego środowiska przyśpiesza oraz ułatwia naszą pracę i daje dodatkowe korzyści w postaci możliwości wykonywania wykresów.
