#AdminCases, czyli gotowa solucja: Permanentna inwigilacja musi trwać czyli jak zebrać logi w jednym miejscu za pomocą rsylog oraz Grafana Loki

Zapewne czytając większość wpisów naszego bloga odnieśliście wrażenie, że w Asseco to sami programiści (no przynajmniej w lwiej większości ;) ), jednak pragnę zapewnić, że nas administratorów czy innych Dev/SysOps-ów też tutaj nie brakuje i dlatego jak rzucili hasło, że prędziorkiem trzeba coś napisać, bo społeczeństwo się domaga to pospieszyłem byłem z odsieczą - a co, nie tylko development będzie się udzielał.
Ave ;)
Programiści też potrzebują mieć swoich bohaterów … i tym właśnie administratorek jest ;)
No dobrze, przejdźmy do problemu nad jakim przyjdzie mi się dzisiaj pochylić i trochę o tym opowiedzieć.
Chcemy, a właściwie powinniśmy czytać logi z naszych serwerów. Jeżeli tych serwerów jest ograniczona ilość i wiemy, że coś się wydarzyło na jakimś konkretnym to prosta piłka. Czyli logujemy się na tenże, szukamy co jest przyczyną naszych udręk wykorzystując zgromadzone tam wpisy. Przeszukiwanie ułatwia nam to, że logi podzielone są na pliki z podsystemów czy usług więc spokojnie znając podstawy systemu i lokalizację zapisów jesteśmy w stanie się tam odnaleźć.
Proste nieprawdaż?
A co, jeżeli mamy bardzo dużo serwerów i dobrze byłoby przeglądać co się na nich dzieje w trakcie normalnej pracy (nawet jeżeli nie wydarzyło się nic konkretnego) ergo standardowa praca administratora. Pomimo tego, że stereotypem niepochlebnej opinii o pracy Admina jest to, że wykonywanie takiej funkcji polega na gaszeniu pożarów jak wystąpią, a reszta czasu to oczekiwanie na taki moment, to jednak większość osób, którzy mieli styczność z tego rodzaju zajęciem, przegląda zdarzenia, które miały miejsce na hostach, monitoruje wysycenie zasobów, czy sprawdza działanie usług, żeby uniknąć jakiś niespodzianek, a te są zmorą każdego szanującego się władcy wśród serwerów, aplikacji czy też każdego tworu, wynalazku czy innego ustrojstwa, którym można administrować. Oczywiście najczęściej gros rzeczy monitorujemy jakimś systemem monitoringu jak na przykład Zabbix czy inny system do tego przeznaczony, gdzie ten poinformuje o problemie, ale później takowy trzeba przeanalizować i dokonać właściwej diagnozy, aby go usunąć.
Oczywiście najprostszym rozwiązaniem - przy którym nie musimy się nawet wysilać - jest zalogowanie się na każdy serwer i zaglądanie do wszystkich, interesujących nas logów. Proste, prawda? Ale upierdliwe do granic możliwości i z całą pewnością taka sytuacja może wyprowadzić z równowagi nawet ascetę zbliżającego się do osiągnięcia stanu nirwany lub przynajmniej ranić danego osobnika szlagiem, bo ani to wydajne, ani też ergonomiczne, a jeżeli do tego wchodzi skala hostów wchodząca w dziesiątki albo i setki to zaczyna być to awykonalne - nawet jeżeli chodzi o samo przeglądanie, nie mówiąc o wyszukiwaniu jakiejś anomalii.
To co właściwie możemy zrobić?
Oczywiście mamy jako alternatywę rozwiązania SIEM, APM czy inne kombajny dla przykładu ELK, Splunk czy Graylog jednak po co od razu zatrudniać armatę do złapania wróbla, tym bardziej, że jeżeli chodzi o samo odkładanie danych i ilości jakie będą gromadzone to może być z tym różnie. Dlatego pokażę na przykładach 2 rozwiązania agregowania logów, gdzie szczególnie to drugie czyli Grafana Loki można rozwinąć wykorzystując dalsze narzędzia od tego vendora, co - zaprawdę powiadam Wam - może utworzyć całkiem fajne narzędzie do szukania co właściwie się stało. Oczywiście dochodzi tutaj jeszcze temat związany z bezpieczeństwem, bo przecież zcentralizowanie logów może pomóc w wyszukaniu jakichś anomalii w naszej infrastrukturze, no i nie trzeba nadawać uprawnień do każdego serwera, aby jakiś guru mógł spojrzeć na logi systemowe w celu diagnozy lub też nawet jak strzeli serwer zawsze będziemy mogli sięgnąć do zapisów, aby wiedzieć co mogło się wydarzyć.
Wspomniałem o 2 rozwiązaniach, o których dzisiaj pogadamy:
- Pierwszy to mechanizm wewnętrzny serwisu rsyslog, który jest dostępny na większości wykorzystywanych obecnie systemów operacyjnych w postaci wysyłania logów na jeden centralny serwer.
- Drugi to wykorzystanie Grafana Loki. Oczywiścię, żeby całość rozwiązania zadziałała jest potrzebne nieco więcej serwisów o czym oczywiście postaram się wspomnieć.
Przejdźmy do tego jak to wszystko skonfigurować, jaka jest charakterystyka poszczególnych rozwiązań i - mówiąc potocznie - jakie są wady i zalety lub też ułatwienia i utrudnienia w implementacji. Oczywiście postaram się to przedstawić w najbardziej przystępny sposób, żeby nawet największy laik mógł sobie to przećwiczyć i dobrać rozwiązanie do własnych potrzeb. Od razu wspominam, że w tej solucji nie będzie wyświetlania via www ale postaram się w jakimś kolejnym odcinku pokazać jak to uczynić ku uciesze gawiedzi w postaci zainteresowanych wykresami, tabelkami czy innymi wizualizacjami, które można unaocznić w przeglądarce, a przy okazji tegoż kolejnego odcinka pokażę jak to działa w kontenerach oraz uruchamiane jako instalacja ręczna i dodanie serwisu żeby już wszyscy działający na każdym poziomie abstrakcji byli ukontentowani.
Na początek zajmijmy się konfiguracją rsyslog tak, aby logi z serwerów lądowały na centralnym serwerze logów. Abyście w razie chęci mieli ochotę poćwiczyć dodam na koniec link do pliku konfiguracyjnego dla oprogramowania, które umożliwia tworzenie środowisk testowych czy developerskich jakim jest tworzony przez Hashicorp Vagrant. Tam powstaną 4 wirtualki w VirtualBox, na których będziemy mogli nasze testy przeprowadzić. Od razu mówię, że nie włączam firewall-i żeby ułatwić sobie tą konfigurację czyli nie musieć wypisywać zaklęć dla Firewalld czy UFW, a wydaje mi się, że te zapisy z tych zapor nie są Wam obce.
Zatem do dzieła. Dodam tylko, że solucja będzie w naprawdę żołnierskich słowach w dodatku bardzo obrazkowa dlatego raczej nie będzie trzeba się wiele zastanawiać, a wszelkie wątpliwości, mam taką nadzieję, że nawet jeżeli wystąpią to zaraz prysną gdzieś w siną dal.
Mamy 4 serwery wirtualne:
- logserver - 192.168.56.14
- centos - 192.168.56.10
- ubuntu - 192.168.56.12
- debian10 - 192.168.56.16
Serwer o nazwie logserver będzie stanowił nasze centralne miejsce przechowywania logów zatem tam zaczniemy nasze prace. Logujemy się na serwer i sprawdzamy czy jest odpalona usługa rsyslog poleceniem:
sudo systemctl status rsyslogd
Wynikiem jaki powinniśmy otrzymać na ekranie jest:
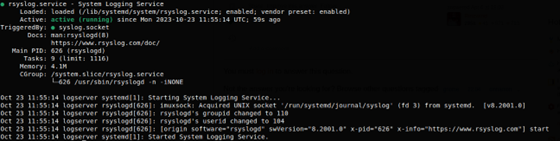
Rsyslog systemd
Serwis rsyslog działa więc możemy przystąpić do konfiguracji, aby nasz serwer logów mógł je przyjmować. Dlatego zajrzyjmy do pliku konfiguracyjnego /etc/rsyslog.conf do sekcji Modules:
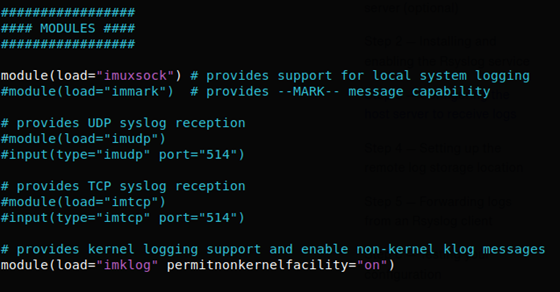
Rsyslog Module
Teraz imudp to komunikacja po protokole UDP, imtcp to komunikacja po protokole TCP, a oba jak widać w konfiguracji zdefiniowane są na port 514. Na potrzeby naszego przykładu ja zdefiniuję komunikację po TCP zdejmując # z poniższych zapisów:
# provides TCP syslog reception module(load="imtcp") input(type="imtcp" port="514")
Po zapisie pliku konfiguracyjnego zrestartujmy serwis i sprawdźmy czy działa. Oczywiście dla tych z włączonymi zaporami to żeby serwer otworzył się na świat trzeba się trochę jeszcze pomęczyć ze zmianą konfiguracji. Tutaj - jak już wcześniej wspomniałem - nie mam podniesionych firewall-i. Wykonujemy polecenie:
sudo systemctl restart rsyslog sudo ss -ntulp|grep 514

Sprawdzenie otwartego portu
W zasadzie to po stronie serwera centralnego pozostaje nam dodać definicję lokalizacji naszych logów. Z racji tego żeby nie zrobił się bałagan ustalamy, że logi znajdą się w katalogu: /var/log/remote, a każdy serwer będzie miał tam odrębny katalog o nazwie hosta. Dodatkowo logi posortujemy na programy, które je generują co powinno ułatwić nam szukanie w razie potrzeby. Jak to zrobić? No bardzo prosto. Musimy ponownie wyedytować /etc/rsyslog.con i dodać następujący wpis:
# # Configuration of remote logs location # $template RemoteLogs, "/var/log/remote/%HOSTNAME%/%PROGRAMNAME%.log" *.* ?RemoteLogs
Jak widać stworzony został template wskazujący w trzecim parametrze na to gdzie mają się znajdować logi i jak mają zostać zapisane. Kolejna linia odpowiada za reguły dla logów systemu linux czyli coś co nazywają facilities oraz priority level - w naszym przypadku wszyskie logi. Robimy restart rsyslog i już jesteśmy w domu - powinien już zbierać i sortować lokalne logi z serwera logserver.
Mała dygresja: jeżeli chcecie inaczej skonfigurować składowanie logów to zapraszam do manuala gdzie można takie rzeczy znaleźć. Osobiście, z racji zarówno ograniczonego czasu jak i chęci zbudowania nieco bardziej zwięzłego tekstu, nie będę się nad każdą opcją rozwodził, to praktyczne przykłady, jak chcesz inne to sobie dopasuj do własnych potrzeb.
Udajmy się teraz drogą logowania ku naszym pozostałym serwerom, aby zdefiniować żeby z łaski swojej zaczęły pchać logi na serwer logserver po TCP na porcie 514. W naszym, przypadku ip serwera logserver to 192.168.56.14 dlatego należy stworzyć taką definicję:
*.* @@192.168.56.14:514
i umieścić ją w syslog.conf (większość systemów z rodziny Red Hat) lub też dla przykładu z rodziny Debiana w /etc/rsyslog.d/50-default.conf. Dla tych, którzy wybrali opcję z protokołem UDP wpis odnośnie wskazania serwera powinien zawierać tylko jedną @.
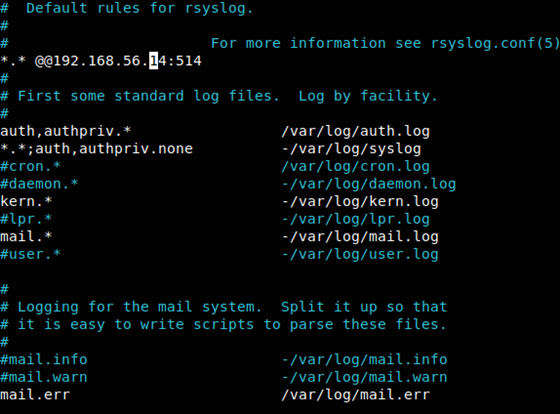
Ubuntu /etc/rsyslog.d/50-default.conf
Modyfikujemy każdy z serwerów i restartujemy na nich usługę rsyslog. Zasadniczo to by było na tyle jeżeli chodzi o konfigurację. Zatem zobaczmy efekty.
Logujemy się na nasz serwer logsever i przechodzimy do katalogu /var/log/remote.

Logserver /var/log/remote
Jak widać powstały katalogi, a poniżej pokażę, że również poszczególne logi z odpowiednim sortowaniem też już są:
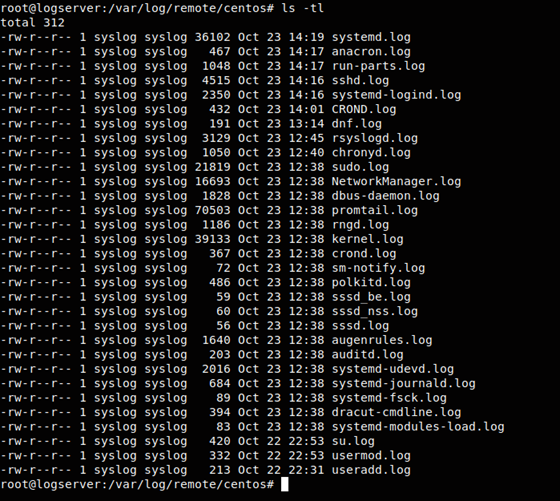
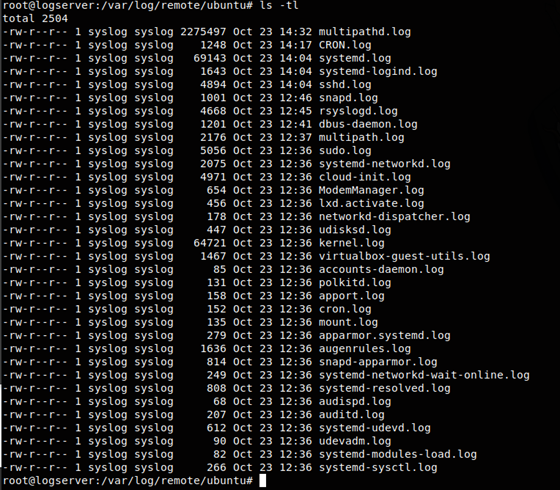
Czad. Wszystko jest. Teraz możemy dla przykładu przeszukiwać nasze logi zgromadzone w jednym miejscu narzędziami linux - chociażby poleceniem grep. Jeżeli znamy się trochę na systemie, a zapewne tak jest to wiemy czego szukać - chociażby błędnych prób logowania via SSH:
grep -r "Failed password" * |grep "^ubuntu"

Przykład przeszukania logów
W ten sposób możemy szukać wszelakich anomalii jakie mogły wystąpić na naszych serwerach, a mając to w jednym miejscu nie musimy latać jak potłuczeni, żeby do tego móc zajrzeć i czego poszukać.
I tym optymistycznym akcentem dokonaliśmy centralizacji logów za pomocą tego co nam rsyslog daje. Wszystko jest właściwie dostępne od ręki, w większości przypadków, czyli na większości systemów nic nie trzeba doinstalowywać, wystarczy trochę zmian w konfiguracjach i efekt “wow” gotowy.
A teraz zrobimy centralizację logów z tym, że wykorzystamy do tego system dedykowany do takich rzeczy jakim jest Grafana Loki.
Grafan Loki to skalowalny, wysoce dostępny, system agregacji logów inspirowany Prometheusem. Został zaprojektowany tak, aby był bardzo ekonomiczny i łatwy w obsłudze. Nie indeksuje zawartości dzienników, ale raczej zestaw etykiet dla każdego strumienia dziennika.
Stopień kompresji danych jest naprawdę imponujący i przede wszystkim sam system nie potrzebuje wielkich zasobów aby działał. Moim zdaniem idealnie nadaje się własnie do gromadzenia logów systemowych, gdzie później można je przeszukać w prosty sposób.
Dzisiaj pokażę trzy komponenty systemu (dwa są niezbędne do działania, a trzeci będzie służył do wyświetlania efektów):
- loki - czyli główny serwer odpowiedzialny za przechowywanie logów oraz przetwarzanie zapytań
- promtail - to agent, odpowiedzialny za zbieranie logów i przekazywanie ich do serwera Loki
- logcli - linia poleceń dla zapytań do lokiego
Oczywiście najlepszą formą wizualizacji dla Grafana Loki jest wykorzystanie Grafany do wyświetlania jednak - jak już wspomniałem - zostanie to przedstawione w innym artykule. Tutaj skupiamy się na gromadzeniu danych w jednym miejscu i prostych zapytaniach, a wizualizacjami i wodotryskami zajmiemy się innym razem, żeby nie zrobić takiego natłoku informacji, że może to przynieść więcej szkody aniżeli pożytku.
W tym przykładzie przedstawię instalację lokalną z repozytorium dla systemów z rodziny Red Hat oraz Debian. Tak samo jak w poprzednim przykładzie serwerem centralnym logów będzie logserver zatem zalogujmy się na niego, a że jest to Ubuntu dlatego trzeba dorzucić do APT repozytorium Grafana za pomocą następującej sekwencji poleceń:
mkdir -p /etc/apt/keyrings/
wget -q -O - apt.grafana.com/gpg.key | gpg --dearmor > /etc/apt/keyrings/grafana.gpg
echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] apt.grafana.com stable main" \
| tee /etc/apt/sources.list.d/grafana.list
Jak już się to udało to możemy zaktualizować listę dostępnych pakietów z repozytorium, a następnie zainstalować loki oraz promtail.
sudo apt update
sudo apt install loki promtail
I teraz podstawowym plikiem konfiguracyjnym dla Grafana Loki jest znajdujący się w /etc/loki plik config.yml, który wygląda następująco:
server:
http_listen_port: 3100
grpc_listen_port: 9096
common:
instance_addr: 127.0.0.1
path_prefix: /tmp/loki
storage:
filesystem:
chunks_directory: /tmp/loki/chunks
rules_directory: /tmp/loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
query_range:
results_cache:
cache:
embedded_cache:
enabled: true
max_size_mb: 100
schema_config:
configs:
- from: 2020-10-24
store: boltdb-shipper
object_store: filesystem
schema: v11
index:
prefix: index_
period: 24h
ruler:
alertmanager_url: localhost
# By default, Loki will send anonymous, but uniquely-identifiable usage and configuration
# analytics to Grafana Labs. These statistics are sent to stats.grafana.org
#
# Statistics help us better understand how Loki is used, and they show us performance
# levels for most users. This helps us prioritize features and documentation.
# For more information on what's sent, look at
# github.com/grafana/loki/blob/main/pkg/usagestats/stats.go
# Refer to the buildReport method to see what goes into a report.
#
# If you would like to disable reporting, uncomment the following lines:
#analytics:
# reporting_enabled: false
Możemy przejść do konfiguracji agenta czyli Promtail. Jest również prosta i napisana w Yaml (/etc/promtail/config.yml) i w wersji pierwotnej - zaraz po zainstalowaniu - wygląda następująco:
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: localhost/loki/api/v1/push
scrape_configs:
- job_name: system
static_configs:
- targets:
- localhost
labels:
job: varlogs
__path__: /var/log/*log
Akurat na serwerze logserver taka konfiguracja by zadziałała jednak chcemy ustawić odpowiednie labele, node i pogrupować logi akurat dla systemu z rodziny Debian, która wiadomo, że nie jest tożsama z tymi z Red hat lub innymi chociażby ze względu na nazewnictwo. Dlatego zatrzymujemy serwis promtail poleceniem:
sudo systemctl stop promtail
a następnie modyfikujemy go na nasze potrzeby wskazując również ip właściwego dla nas serwera Loki czyli 192.168.56.14 na porcie 3100:
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: 192.168.56.14/loki/api/v1/push
scrape_configs:
- job_name: system
static_configs:
- targets:
- localhost
labels:
job: varlogs
node: "logserver"
__path__: /var/log/{alternatives.log,auth.log,bootstrap.log,cloud-init.log.dmesg,dpkg.log,kern.log,syslog,ubuntu-advantage.log,ubuntu-advantage-timer.log}
- job_name: journal-var
journal:
json: false
max_age: 12h
path: /var/log/journal
labels:
job: systemd-journal
node: "logserver"
relabel_configs:
- source_labels: ['__journal__systemd_unit']
target_label: 'unit'
- url - wskazuje na nasz serwer loki
- w definicji jobów mamy 2:
- - system - gdzie ma etykietę zadania: varlogs, wskazanie na node jakim jest logserver oraz wskazanie ścieżek do logów jakie ma zbierać
- - journal-var - etykieta zadania: systemd-journal, wskazanie node-a: logserver, w path mamy ściężkę gdzie znajduje się journal
Teraz musimy nadać uprawnienia użytkownikowi promtail, inaczej będzie nas opluwał, że nie dostać się do plików logów i tym bardziej gdzieś ich przesłać. Z racji, że jesteśmy na Ubuntu czyli rodzinie Debian najprościej jest dodać użytkownika promtail do grupy adm:
sudo usermod -aG adm promtail
Teraz pozostaje tylko włączyć usługę promtail i voila - gotowy serwer centralny ;)
Pozostałe serwery z naszego przykładu nie potrzebują już instalacji Grafana Loki, dlatego ograniczamy sie tylko do instalacji Promtail, a reszta jeżeli chodzi o rodzinę Debian jest taka sama.
Pochylę się jeszcze na momencik nad linuksami z rodziny Red Hat. Żeby nie było problemów dam przykład jak tam uczynić wszystko co niezbędne, aby było podobnie. Logujemy się na serwer z rodziny czerwonego kapelusza i dokonujemy wpisu następującej treści w definicji repozytorium Yum/Dnf (/etc/yum.repos.d/grafana.repo):
[grafana] name=grafana baseurl=https://rpm.grafana.com repo_gpgcheck=1 enabled=1 gpgcheck=1 gpgkey=https://rpm.grafana.com/gpg.key sslverify=1 sslcacert=/etc/pki/tls/certs/ca-bundle.crt
A dalej już z górkii, aktualizacja, instalacja promtail, zatrzymanie serwisu promtail:
sudo dnf update sudo dnf install promtail sudo systemctl stop promtail
I teraz modyfikacja pliku konfiguracyjnego pod rodzinę Red Hat (pamiętajcie, że słowo klucz node dotyczy nazwy serwera):
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: 192.168.56.14/loki/api/v1/push
scrape_configs:
- job_name: system
static_configs:
- targets:
- localhost
labels:
job: varlogs
node: "centos"
__path__: /var/log/{messages,secure,dmesg,maillog,yum.log,dnf.log,boot.log,cron}
- job_name: journal-run
journal:
json: false
max_age: 12h
path: /run/log/journal
labels:
job: systemd-journal
node: "centos"
relabel_configs:
- source_labels: ['__journal__systemd_unit']
target_label: 'unit'
Teraz uprawnienia dla plików logów. Tutaj robimy trochę inaczej bo musimy ustawić listy kontrolne, w tym przypadku na konkretne pliki na użytkownika promtail:
cd /var/log
sudo setfacl -m u:promtail:r ./messages
sudo setfacl -m u:promtail:r ./secure
sudo setfacl -m u:promtail:r ./cron
sudo setfacl -m u:promtail:r ./dnf*
sudo setfacl -m u:promtail:r ./maillog
Po uruchomieniu serwisu promtail powinno wszystko działać i logi powinny byc przekazywane do Loki. Powtarzamy procedurę z promtail na wszystkich interesujących nas serwerach. Teraz przejdźmy do serwera centralnego i zainstalujmy klienta linii poleceń czyli logcli:
sudo apt install logcli
W przypadku gdy mamy serwer lokanie nie trzeba nic robić ewentualnie wyeksportować zmienną:
export LOKI_ADDR=localhost
A teraz zadajmy parę zapytań, żebyśmy się przekonali czy faktycznie mamy dane do analizy. Zacznijmy od labels:

Przykład logcli series
Wisienka na torcie czyli w końcu zadajmy pytanie, które zwróci nam dane ze logów - użyjmy logcli query. Nie będę dawał tutaj wielu przykładów, bo przecież to możecie z powodzeniem poszukać sobie sami sięgając do dokumentacji dla queries w Loki i logcli ale zadam to jedno, których danych szukaliśmy w tym co zgromadziliśmy za pomocą rsyslog. Zapytanie będzie wyglądało mniej więcej tak bo musicie pamiętać, że ilość danych jak i ramy czasowe są ograniczone jeżeli nie są w atrybutach dlatego zadam takie polecenie:
logcli query --timezone=UTC --from="2023-10-22T00:00:00Z" \ '{node="ubuntu"}|= "Failed password"' --limit=10000
A wynikiem będzie:

Przykład logcli query
No i jak widać są wyniki i do tego zawierają to co mieliśmy przy podobnym zapytaniu w przypadku rsyslog więc jak to powiedział Zagłoba: „No to żeśmy Bohuna usiekli”.
No dobrze to przejdźmy do konkluzji: agregowanie danych logów w jednym miejscu, jak widać w tekście nie jest aż tak trudne na jakie wygląda, a jednak daje bardzo dużo korzyści chociażby ze względu na dostęp do danych czy bezpieczeństwo. W zasadzie to nie będe wypowiadał się w kwestii, które jest lepsze, bo wybór należy do administratora czy jakiegoś bossa, który o tym decyduje. Ja, ze swojej strony, opisałem dwa modele takiego rozwiązania wraz z dość dokładnym opisem co może stanowić dla kogoś jakieś wstępne Howto i ewentualny pomysł na całe rozwiązanie jakie jesteście lub będziecie chcieli wrzucić u siebie i z niego korzystać. Gorąco namawiam do takiej pozytywnej inwigilacji, która naprawdę może ułatwić Wam życie. Postaram się, aby ten temat jeszcze rozwinąć, chociażby o wspomnianą Grafanę i wykorzystanie kontenerów, ale to jak mówił Moks z filmu Vabank to już „Następną razą” i oczywiście mam nadzieję, że ta „raza” wystąpi jak najszybciej - o ile czas mi na to pozwoli bo oczywiście chęci są zawsze.
P.S.Tutaj zostawiam Wam plik Vagrantfile do tego artykułu chociaż uprzedzam, że mogę go jeszcze modyfikować, bo wiele rzeczy robiłem ręcznie - już po wygenerowaniu serwerów zatem mogą się jeszcze trochę pozmieniać.
W razie pytań czy niejasności zapraszam do kontaktu.
