Gdzie ten pomidor? Czyli detekcja obiektów z tensorflow w skrócie

Postanowiłam w tym artykule zaprezentować jedno z wielu zagadnień z zakresu sztucznej inteligencji – wykrywanie obiektów, ponieważ to ono właśnie stanowi podstawę rozwiązywania bardziej złożonych problemów z wykorzystaniem AI.
Skłamałabym stwierdzając, że poziom skomplikowania procesu jest porównywalny ze złożonością przepisu na dobrą zupę pomidorową babci. Faktycznie – przygotowanie składników trochę trwa, a efekty dają sporo satysfakcji i tutaj kończy się ta analogia. Czasami pojawiają się błędy, które należy rozwiązać, a uczenie sieci neuronowej zajmuje dużo czasu, liczę jednak na Waszą cierpliwość i dzielne przebrnięcie ze mną przez ten artykuł :)
Sama detekcja obiektu na obrazie polega przede wszystkim na określeniu lokalizacji jego cech charakterystycznych, na podstawie których miałby zostać sklasyfikowany.
Załóżmy, że chcemy stworzyć narzędzie do wykrywania pomidorów na fotografiach z wykorzystaniem Tensorflow.
Aby misja ta zakończyła się sukcesem, musimy spełnić następujące warunki:
- Przygotować zbiór danych
- Wytrenować na ich podstawie model dla naszego detektora
- Wykorzystać gotowy model w systemie
Brzmi łatwo, prawda? W takim razie do dzieła!
*Uwaga Polecenia konsolowe zaprezentowane w niniejszym artykule są wykonywane na systemie MacOS.
Przygotowanie środowiska roboczego
Na potrzeby prezentacji rozwiązania założyłam na pulpicie katalog tomato_detection, w obrębie którego będę się poruszać, a także folder tomato_detection/workspace. Pełen kod rozwiązania dostępny jest pod adresem repozytorium.
Konfiguracja narzędzi
Instalacja Python’a
Warto na początek zainstalować środowisko Python’a, ponieważ skrypty, które będziemy uruchamiać są napisane właśnie w tym języku. Ponadto, konieczna będzie instalacja poniższych pakietów przez wzgląd na wykorzystanie ich w skryptach.
// Instalacja Python’a
> brew install python
Instalacja TensorFlow
Jeśli jeszcze nie słyszeliście o TensorFlow, polecam zapoznanie się z informacjami na oficjalnej stronie. W skrócie – Tensorflow, to narzędzie służące głównie do przygotowywania modeli wykorzystywanych w uczeniu maszynowym. Proces instalacji dokładnie opisano tutaj, niemniej jednak na MacOS sprowadza się do wykonania polecenia:
// Instalacja TensorFlow
> pip install tensorflow
Instalacja TensorFlow Object Detection API
Przydatne jest również TensorFlow Object Detection API, którego instalację z kolei omówiono tutaj. TF Object Detection API, to zbiór materiałów, które można wykorzystać do pełnego przeprowadzenia procesu uczenia modelu w określonych zagadnieniach – od analizy tekstu, przez badanie mowy, aż po interpretację obrazu. Po sklonowaniu repozytorium API powinniśmy otrzymać folder models w lokalizacji instalacji (w moim przypadku w tomato_detection).
// Klonowanie repozytorium API
> git clone https://github.com/tensorflow/models.git
Interfejs API Tensorflow Object Detection używa Protobufs do konfigurowania modelu i parametrów szkoleniowych. Przed użyciem frameworka, biblioteki Protobuf muszą zostać pobrane i skompilowane. Przeprowadzamy instalację zgodnie z instrukcją. Bardzo ważne jest to, żeby zwracać uwagę, w jakiej lokalizacji wywołuje się poszczególne polecenia.
Następnie do lokalizacji models/research kopiujemy skrypt konfiguracyjny setup.py, po czym go uruchamiamy. Dzięki niemu zainstalowane zostaną wszystkie zależności niezbędne podczas realizacji skryptów uczących.
//Kopiowanie skryptu konfiguracyjnego do bieżącej lokalizacji
> cp object_detection/packages/tf2/setup.py .
// Uruchomienie skryptu konfiguracyjnego
> sudo python setup.py install
Warto przetestować instalację Protobufs i konfiguracji z wykorzystaniem polecenia:
> python object_detection/builders/model_builder_tf2_test.py
Powinno się otrzymać listing zbliżony do poniższego.
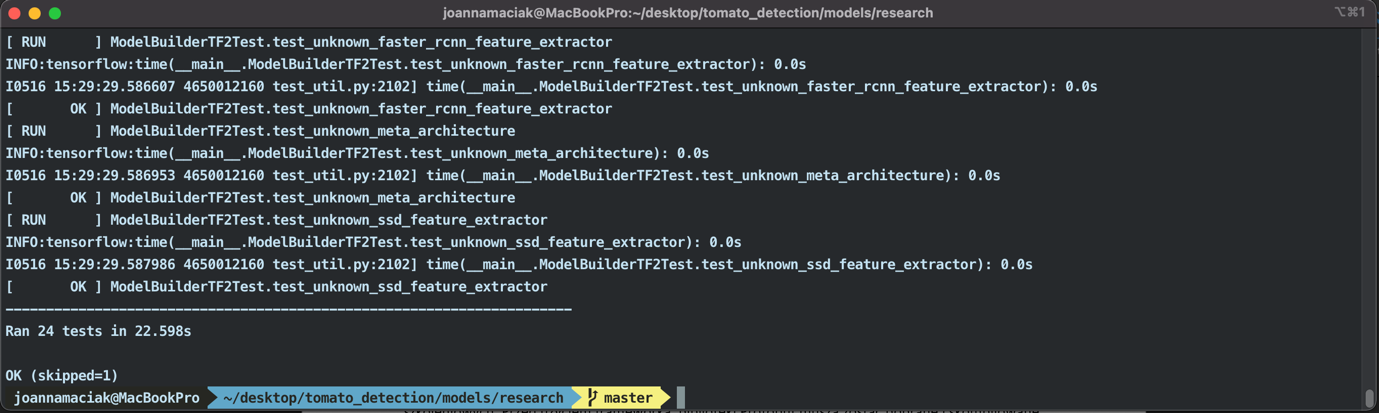
Przygotowanie zbioru danych
Zanim przejdziemy do uczenia modelu, powinniśmy przygotować tzw. zbiór uczący i zbiór testujący, czyli takie zbiory danych, w oparciu o które będziemy w stanie uczyć nasz wykrywacz (czyt. model) i weryfikować jego dokładność. Będziemy potrzebować zbioru fotografii, na których oznaczono pomidory oraz definicje tych „oznaczeń”, zwane później adnotacjami.
Ręczne pobieranie i oznaczanie fotografii z pomidorami może być czasochłonne, dlatego z odsieczą przybywa platforma Kaggle, gdzie znajdziemy gotowe, odpowiednio spreparowane zbiory danych. Skorzystamy tutaj z już oznaczonego zbioru danych Tomato Detection, który pobierzemy ze strony Kaggle – został on podzielony na dwa moduły:
- images, zwierający fotografie, na których możemy zlokalizować pomidor
- annotations, w którym przygotowano pliki XML opisujące dokładną lokalizację pomidorów
na zdjęciach referencyjnych w module images.
*Oba pobrane moduły przenosimy do folderu roboczego tensorflow.
Tensorflow Object Detection API korzysta z formatu pliku TFRecord, musimy więc przekonwertować nasz zbiór danych na ten format. Istnieje kilka opcji generowania plików TFRecord.
W pierwszej zakładamy, że mamy zbiór danych, który ma podobną strukturę do zbioru danych Pascal VOC lub Oxford Pet – tutaj wykorzystujemy gotowe skrypty dla konkretnego przypadku (skrypty znajdziecie tutaj). Jeśli jednak nie mamy danych uporządkowanych w jednej z tych struktur, należy napisać własny skrypt, aby wygenerować TFRecord (dane wejściowe muszą spełniać określone wymagania).
Na szczęście druga opcja nas nie dotyczy, ponieważ mamy dane w formacie Pascal VOC.
Przygotowanie pliku wejściowego dla API
Aby przygotować plik wejściowy dla API, trzeba wziąć pod uwagę dwie rzeczy: po pierwsze, potrzebujemy obrazu RGB, który jest zakodowany jako JPEG lub PNG (moduł images), a po drugie potrzebujemy listy obwiedni (moduł annotations) dla obrazu i klasy (etykiety) obiektu w obwiedni.
W naszym przypadku przypisanie etykiety jest łatwe, ponieważ mamy tylko jedną klasę - pomidor. Przez wzgląd na to, że proces uczenia wymaga przygotowania zbioru wykorzystywanego w uczeniu modelu i zbioru do późniejszej weryfikacji uczenia, dokonamy na zbiorze obrazów i adnotacji podział jednym z najpopularniejszych ze sposobów.
Podział prosty polega na rozgraniczeniu zbioru na dwie części z zachowaniem proporcji między nimi. Zwykle stosunek ten wynosi 9: 1, tj. 90% obrazów jest używanych do treningu, a pozostałe 10% jest utrzymywanych do testów, ale można wybrać stosunek, który odpowiada danemu problemowi.
Na czas uczenia ma znaczący wpływ rozmiar zbioru danych i rozmiary pojedynczych plików. Do celów demonstracyjnych wybrałam więc 50 fotografii, które przeskalowałam do rozmiaru 10-krotnie mniejszego, niż aktualny (skrypt reduce_size.py). Ponieważ były to pliki o rozmiarze 500x400, otrzymałam pliki o rozmiarze 50x40 – oczywiście liczyłam się z utratą jakości tych fotografii, jednak możliwości sprzętowe nie zawsze pozwalają na „szaleństwo” z wykorzystanymi danymi.
Z tych 50 fotografii wyodrębniłam więc losowo zbiór uczący i testowy w stosunku 9:1 wyodrębniając 5 elementów do folderu test, a pozostałe przenosząc do folderu train.
Bieżąca zawartość folderu tomato_detection/workspace/dataset powinna prezentować się następująco:

Za pomocą skryptu convert_xml_to_csv.py zamieniamy pliki adnotacji XML na pojedynczy plik CSV, gdzie na każdy plik XML przypada tyle wierszy CSV, ile wyznaczono obiektów <object/> w pliku XML (ile wyszukiwanych obiektów znajduje się na zdjęciu referencyjnym). Po wykonaniu poniższego polecenia, powinniśmy otrzymać dwa pliki CSV – po jednym dla każdego ze zbiorów (trenującego i testowego).
Uwaga!
Pamiętamy o tym, że przeskalowaliśmy zdjęcia, w związku z czym współrzędne ramek również wymagają przeskalowania o ten sam współczynnik.
> python convert_xml_to_csv.py
Generowanie plików wejściowych skryptu uczącego
Mając wygenerowane pliki adnotacji dla każdego z podzbiorów, za pomocą skryptu generate_record.py generujemy pliki wejściowe TFRecords. Skrypt ten iteruje przez wszystkie pliki *.xml w folderach images/train i images/test i generuje plik *.record dla każdego z nich. Należy zaznaczyć, że w celu uwzględnienia większej liczby klas, które model powinien rozróżniać, trzeba zmodyfikować odpowiednio fragment kodu w skrypcie generate_record.py:
def class_text_to_int(row_label):
if row_label == 'tomato':
return 1
else:
return None
Wartości row_label odpowiadają tutaj wartościom atrybutu name obiektów zawartych w plikach adnotacji XML.
<object>
<name>tomato</name>
</object>
Generowanie plików TFRecords przeprowadzamy za pomocą poleceń:
> python generate_record.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record
> python generate_record.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record
W wyniku tych operacji powinniśmy uzyskać strukturę dataset analogiczną do poniższej:
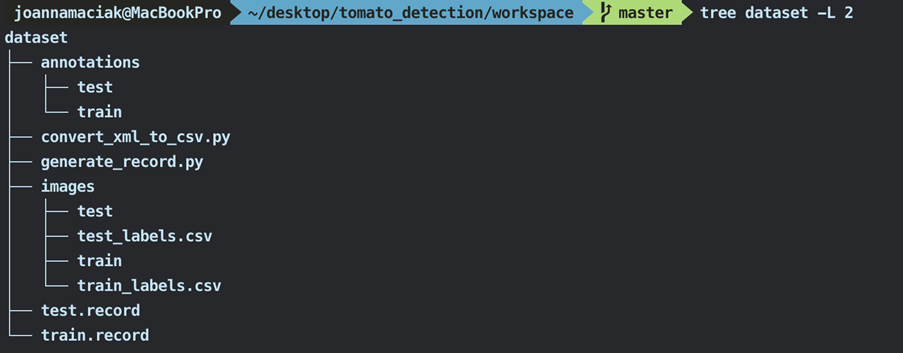
Łatwo zauważyć podział na zbiory testujący i uczący. Wygenerowane pliki CSV znajdują się w folderze images, natomiast pliki *.record zostały wygenerowane w lokalizacji wywołania skryptu generate_record.py.
Konfiguracja uczenia
Ostatnim wyzwaniem, jakie nas czeka jest utworzenie tzw. mapy etykiet oraz pliku konfiguracyjnego.
PLIK MAPY ETYKIET
Pliki map etykiet mają rozszerzenie *.pbtxt. Trzeba pamiętać, że mapowanie wartości id na name powinno być analogiczne do tego w pliku generate_record.py:
item {
id: 1
name: tomato
}
Zapisujemy ten plik jako labels.pbtxt.
Wybór wstępnie wytrenowanego modelu
Model, którego będziemy używać w moim przykładzie, to model Faster ResNet152 V1 640x640, ponieważ zapewnia stosunkowo dobry kompromis między wydajnością a szybkością, a ponieważ zależy nam na podwyższonej dokładności, wybrałam model o większej liczbie warstw (152 zamiast podstawowej 50). Istnieje jednak wiele innych modeli, z których można korzystać, a wszystkie są wymienione w Zoo TensorFlow 2 Detection Model. Różnice pomiędzy poszczególnymi sieciami ResNet zostały dokładnie omówione w artykule na portalu Neurohive. Pobieramy więc do naszego folderu workspace model Faster R-CNN ResNet152 V1 640x640.
Model ten będzie potrzebny w dalszych krokach - na potrzeby tego postu nie będziemy tworzyć zadania szkoleniowego od zera, ale reużyjemy model dostarczony przez TensorFlow. Jeśli chcecie wytrenować zupełnie nowy model, możecie zapoznać się z samouczkiem TensorFlow.
PLIKI KONFIGURACJI SZKOLENIA I MODELU
Interfejs API TensorFlow Object Detection używa plików Protobuf do konfigurowania procesu uczenia i oceny. Szkielet pliku konfiguracyjnego wygląda w następujący sposób:
model: {
// Tutaj określamy, jaki typ modelu będzie trenowany (np. metaarchitektura,
// ekstraktor cech)
}
train_config: {
// Tutaj definiujemy, jakie parametry powinny być używane do uczenia parametrów
// modelu (tj. Parametry SGD, wstępne przetwarzanie danych wejściowych i wartości
// inicjalizacji ekstraktora cech)
}
train_input_reader: {
// Tu wskazujemy zestaw danych, na którym model powinien zostać przeszkolony.
}
eval_config: {
// Tutaj określamy, jaki zestaw metryk zostanie zgłoszony do oceny.
}
eval_input_reader: {
// Tu wskazujemy zestaw danych, na którym model będzie oceniany, powinien być inny // niż zestaw uczący
}
Istnieje wiele opcji dla pola model do skonfigurowania. Najlepsze ustawienia będą zależeć od danej aplikacji. Modele Faster R-CNN są lepiej dostosowane do przypadków, w których wymagana jest wysoka dokładność, a opóźnienie ma niższy priorytet. I odwrotnie, jeśli najważniejszym czynnikiem jest czas przetwarzania, zalecane są modele z dyskami SSD. My nie wykonujemy przetwarzania obrazu w czasie rzeczywistym (np. przetwarzania obrazu wideo), nie wykonujemy też detekcji na ogromnym zbiorze danych - zależy nam na wysokiej dokładności, dlatego skonfigurujemy model Faster R-CNN.
Aby pomóc nowym użytkownikom w rozpoczęciu pracy, w folderze models/research/object_detection/samples/configs udostępniono przykładowe konfiguracje modeli. Zawartość tych plików konfiguracyjnych można wkleić do pola model w pliku konfiguracji, przy czym należy tutaj zwrócić uwagę, że pole num_classes powinno zostać zmienione na wartość odpowiednią dla zbioru danych.
My natomiast, gdy pobraliśmy i wyodrębniliśmy wstępnie wytrenowany model, możemy stworzyć katalog dla zadania szkoleniowego.
W obszarze workspace/models utworzymy nowy katalog o nazwie fast_resnet152_v1 i skopiujemy plik workspace/faster_rcnn_resnet152_v1_640x640_coco17_tpu-8/pipeline.config do nowo utworzonego katalogu.
Wartości, które powinniśmy zmodyfikować w pliku pipeline.config dla naszego przykładu:
- model.faster_rcnn.num_classes = 1 (liczba klas do rozróżnienia – u nas jedna – „pomidor”)
- train_config.fine_tune_checkpoint = faster_rcnn_resnet152_v1_640x640_coco17_tpu-8/checkpoint/ckpt-0 (ścieżka do punktu kontrolnego)
- train_config.fine_tune_checkpoint_type = „detection” (zamiana z klasyfikacji na detekcję)
- train_config.use_bfloat16 = false (zamiana, jeśli nie uczymy na TPU)
- train_input_reader.label_map_path = „absolute_path/labels.pbtxt” (ścieżka bezwzględna do pliku map etykiet)
- train_input_reader.tf_record_input_reader.input_path = „absolute_path/train.record” (ścieżka bezwzględna do pliku record dla zbioru uczącego)
- eval_input_reader.label_map_path = „absolute_path/labels.pbtxt” (ścieżka bezwzględna do pliku map etykiet)
- eval_input_reader.tf_record_input_reader.input_path = „absolute_path/test.record” (ścieżka bezwzględna do pliku record dla zbioru testującego)
Uczenie MODELU
Przed przystąpieniem do uczenia modelu skopiujemy skrypt uczący do lokalizacji tomato_detection/workspace:
> cp ../models/research/object_detection/model_main_tf2.py .
> python model_main_tf2.py --model_dir=models/trained_model --pipeline_config_path=models/pipeline.config --alsologtostderr
Terminal będzie wydawał się „zawieszony”, ale nie należy spieszyć się z anulowaniem procesu.
Dane wyjściowe treningu domyślnie rejestrują tylko co 100 kroków, dlatego w setnym kroku powinien zostać wyświetlony dziennik strat. Czas oczekiwania może się znacznie różnić w zależności od tego, czy używacie GPU i od wybranej wartości batch_size w pliku konfiguracyjnym (im wyższa, tym więcej pamięci jest wykorzystywane), więc bądźcie cierpliwi.
Nauka modelu polega na tym, że parametry wykorzystanego modelu są modyfikowane na podstawie odpowiedniego wykorzystania zbioru uczącego, a potem następuje weryfikacja, jak bardzo ten etap nauki się powiódł poprzez próbę detekcji na zbiorze testowym.
Rezultaty uczenia można obserwować w konsoli – należy obserwować wartość loss. Jest to tzw. strata i oznacza, jak bardzo nasz model się pomylił w detekcji elementów testujących po danym cyklu nauki. Im jej wartość jest niższa tym lepiej. Gdy zaczniemy obserwować w pewnym momencie stały wzrost tej wartości, to oznacza, że przeuczyliśmy nasz model, co nie jest zjawiskiem korzystnym. Przy zbyt długim uczeniu sieć neuronowa nadmiernie uzależnia swoje działanie od elementów wykorzystanych w zbiorze uczącym i staje się bezużyteczna w analizie nowych obiektów. Można ją wtedy porównać do osoby, która owszem, ma sporą wiedzę, natomiast nie potrafi jej wykorzystać w sytuacjach, których nie poznała.
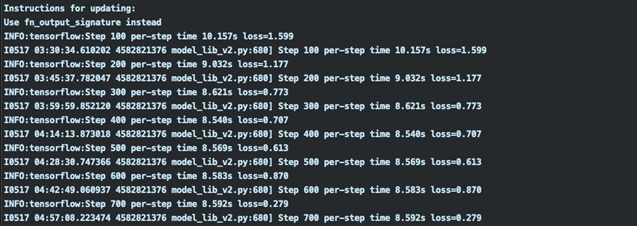
Gdy stwierdzimy, że nasz model jest satysfakcjonująco dobrze nauczony wykrywania pomidorów,
Przerywamy proces uczenia (np. zamykając okno terminala). Aby ułatwić korzystanie z modelu i wdrażanie go, zaleca się przekonwertowanie go na tzw. zamrożony plik grafu. Można to zrobić za pomocą skryptu exporter_main_v2.py, który kopiujemy z tomato_detection/models/object_detection
do tomato_detection/workspace/models.
Uruchamiamy polecenie do generowania modelu z następującymi parametrami:
> python exporter_main_v2.py --input_type image_tensor
--pipeline_config_path pipeline.config
--trained_checkpoint_dir trained_model
--output_directory trained_model/inference_graph
Musieliśmy tutaj zdefiniować typ parametrów wejściowych, ścieżkę do pliku konfiguracji procesu uczenia, ścieżkę do wygenerowanych w procesie uczenia plików punktu kontrolnego oraz folder docelowy dla naszego modelu. W wyniku tej operacji pojawił nam się katalog tomato_detection/models /trained_model/inference_graph.
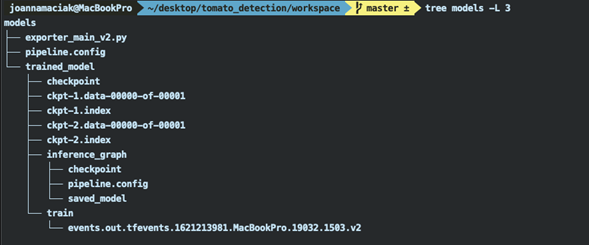
Plik, który wykorzystamy, to w kolejnym etapie, to saved_model.pb.
Wykorzystanie modelu w praktyce
Nadeszła „chwila prawdy” – czas na wykorzystanie wygenerowanego przez nas modelu do wykrywania pomidorów na fotografiach.
Z pobranego na początku zbioru wybrałam kilka zdjęć, które nie zostały wykorzystane ani do uczenia, ani do testowania modelu, a następnie za pomocą skryptu detect_tomatos.py oznaczyłam na tych fotografiach obszary, w których, według naszego modelu znajdują się pomidory. Efekty są zadowalające biorąc pod uwagę rozmiar zdjęć narzucony w procesie uczenia oraz rozmiar zbioru danych wykorzystanych do uczenia.



Skrypt do prezentacji detekcji wygląda na obszerny, jednak znaczną część stanowi inicjalizacja zmiennych.
Metodę główną main() otwiera linijka odpowiedzialna za załadowanie wytrenowanego grafu do pamięci:
detect_fn = tf.saved_model.load(PATH_TO_SAVED_MODEL)
Następnie inicjalizowana jest zmienna określająca kategorie w oparciu o uzyskany identyfikator klasy:
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS,
use_display_name=True)
Później każde ze zdjęć jest przetwarzane w taki sposób, aby spełniać warunki danych wejściowych dla detektora. W tym celu otwierane są jako tablice o odpowiednim rozmiarze. Po tym procesie wykonywana jest detekcja za pomocą metody detect_fn(input_tensor).
detections = detect_fn(input_tensor)
Ramki w detections (tablica wektorów detections['detection_boxes']) są uporządkowane od tej, dla której wyznaczono najwyższą pewność detekcji (score), po tą, dla której ten procent ukształtował się na najniższym poziomie.
Poniższy fragment służy już stricte wizualizacji wyników. Pozwoliłam sobie ograniczyć liczbę wyświetlanych ramek do maksymalnie 10, narzucając jednocześnie minimalną pewność detekcji 90%.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np_with_detections,
detections['detection_boxes'],
detections['detection_classes'],
detections['detection_scores'],
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=10,
min_score_thresh=.90,
agnostic_mode=False)
Podsumowanie
Wpływ na czas uczenia modelu ma w znacznej mierze od zbiór danych i możliwości naszego sprzętu. Nie ma jednak rzeczy niemożliwych, odpowiednia konfiguracja procesu uczenia otwiera nam możliwość stworzenia własnego, dopasowanego do indywidualnych potrzeb narzędzia.
Proces uczenia maszynowego własnego detektora wymaga odrobiny cierpliwości, ponieważ bardzo łatwo popełnić błędy konfiguracji owocujące niepoprawnie wytrenowanym modelem. Mimo, że całość wygląda skomplikowanie, to nie warto się zniechęcać – w sieci krąży mnóstwo pomocnych artykułów w tym zakresie, a i sam TensorFlow uzbraja nowych użytkowników w szereg narzędzi, dzięki którym uczenie maszynowe nie jest takie straszne :)
