Hadoop dla .NET Developerów W przykładach dla .NET Core Część 1

Jednym z pierwszych kompleksowych rozwiązań dla Big Data jest projekt rozwijany przez fundacje Apache o nazwie Apache Hadoop.
Jest to rozwiązanie z otwartym kodem napisane w języku Java. Do jego głównych założeń należało przetwarzanie wielkich zbiorów danych za pomocą klastrów komputerowych. Jego wszystkie części zaprojektowano tak, by uniezależnić rozwiązanie od naturalnie pojawiających się awarii sprzętowych. System charakteryzować miała wysoka niezawodność (HA – High Availability).
W Apache Hadoop możemy wyróżnić następujące moduły:
- Hadoop Distributed File System (HDFS) – rozproszony system plików
- Hadoop YARN (Yet Another Resource Negotiator) – platforma do zarządzania zasobami klastra
- Hadoop MapReduce– implementacja paradygmatu MapReduce do przetwarzania dużych ilości danych.
HDFS (Hadoop Distributed File System)
HDFS jest to rozproszony system plików, którego główną cechą, jak całego rozwiązania Hadoop, jest wysoka odporność na występujące awarie. Celem tego rozwiązania jest możliwość przetrzymywania dużych zbiorów danych oraz wysoka skalowalność takiego rozwiązania. W HDFS możemy wyróżnić dwie główne części (węzły klastra):
- DataNode - węzeł klastra Hadoop odpowiedzialny za przechowywanie danych
- NameNode - węzeł klastra Hadoop odpowiedzialny za zarządzanie przechowywanymi danymi na DataNode. Odpowiedzialny jest za sterowanie replikacjami danych oraz umożliwia dostęp do danych za pomocą aplikacji uruchomionych na klastrze Hadoop oraz za pomocą aplikacji zewnętrznych.
Spójrzmy teraz dokładnie jak działa HDFS.
Zgodnie ze Schematem 1 można zauważyć, że wszystkie zapytania do HDFS kierowane są najpierw to NameNode, a on dopiero potem przekierowuje inne aplikacje na klastrze do odpowiednich danych na poszczególnych DataNode. NameNode trzyma meta informacje o strukturze katalogów i plików i zarządza zapisem, odczytem oraz replikacją danych między poszczególnym DataNode.
Schemat 1
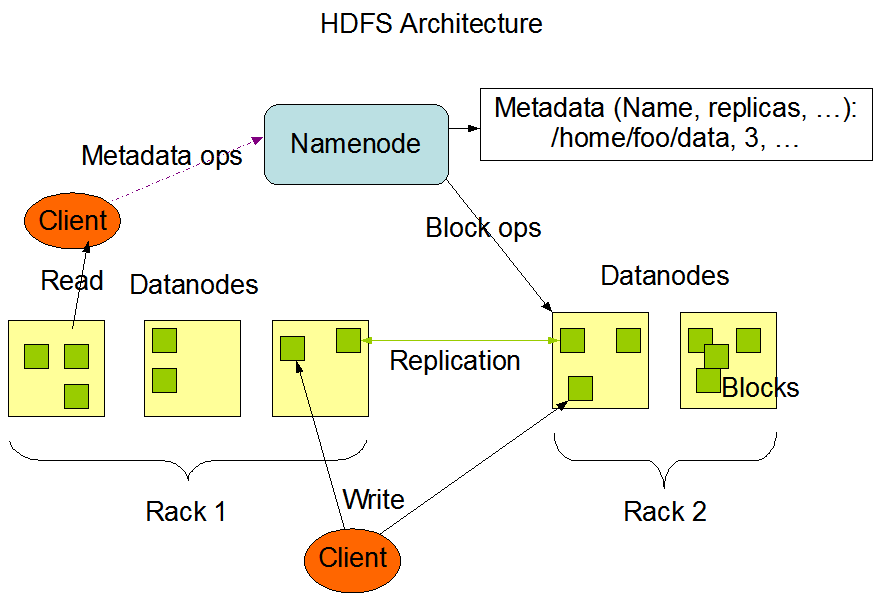
Jakimi zasadami kieruje się replikacja danych? Najmniejszą niepodzielną część informacji zapisaną na HDFS nazywamy blokiem. Standardowy rozmiar bloku wynosi 64MB. NameNode replikuje dane używając bloków. Schemat działania replikacji bloków możemy zauważyć na Schemacie 2. W celu zapewnienia wysokiej dostępności każdy blok replikowany jest standardowo przynajmniej 3-krotnie by zapewnić wysoką dostępność po awarii jednego lub wielu DataNode.
Schemat 2
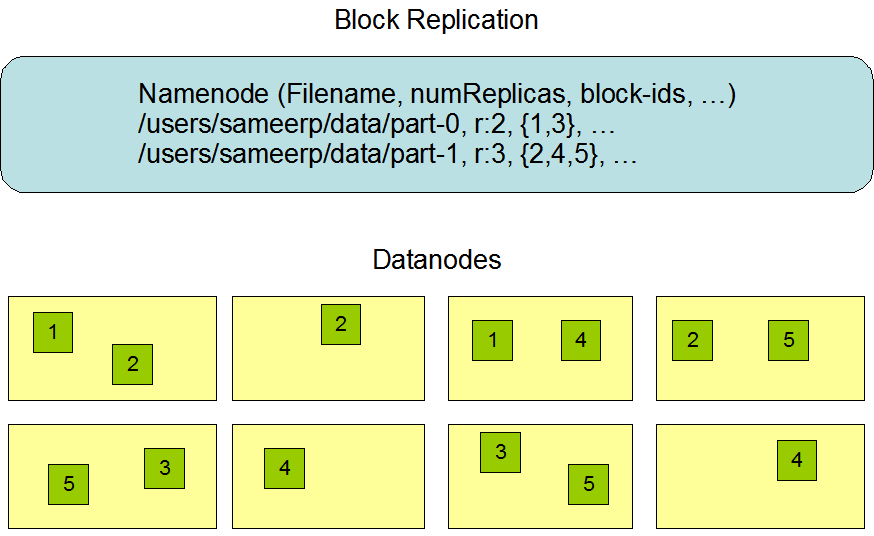
System plików HDFS ma strukturę drzewiastą i wzorowany jest na systemie plików Unixowych. Posiada system uprawnień podobny do systemu unixowego czyli składa się z prawa właściciela, grupy oraz użytkownika. Każde prawo reprezentowane jest w ten sam sposób, co w systemach Unixowych za pomocą ciągu literek “rwx” lub jej reprezentacji liczbowej od 0 do 7 dla każdego uprawnienia.
YARN (Yet Another Resource Negotiator)
Jest to zbiór usług zarządzających uruchamianiem zadań na klastrze Hadoop. W szczególności programów w paradygmacie MapReduce.
Składa się z następujących części:
- Resource Manager
- Scheduler - odpowiedzialny jest za przydzielanie zasobów uruchamianym aplikacjom na klastrze. Harmonogram jest czystym harmonogramem w tym sensie, że nie monitoruje ani nie śledzi stanu aplikacji. Harmonogram wykonuje swoją funkcję planowania w oparciu o wymagania zasobów aplikacji; robi to w oparciu o abstrakcyjne pojęcie zasobu, który zawiera elementy takie jak pamięć, procesor, dysk, sieć itd.
- Applications Manager - jest odpowiedzialny za przyjmowanie zgłoszeń roboczych,
- NodeManager- to agent struktury na komputerze, który odpowiada za kontenery, monitoruje wykorzystanie zasobów (procesor, pamięć, dysk, sieć) i raportuje to samo do ResourceManager / Scheduler.
Przyjrzyjmy się teraz dokładnie działaniu tego modułu Hadoop.
Zgodnie ze Schematem 3 widzimy, że w celu uruchomienia programu na klastrze następuje komunikacja z ResourceManager, by uzyskać odpowiednie zasoby do klastra. ResourceManager informacje te pozyskuje od poszczególnych NodeManager , które raportują mu takie informacje. NodeManager służy również do uruchomienia odpowiednich programów przydzielonych im przez ResourceManager w przygotowanych dla tego celu kontenerach. W trakcie działania programu ResourceManager udostępnia także informację o stanie programów czyli o ich postępie, błędach wykonania oraz zakończeniu danych programów.
Schemat 3
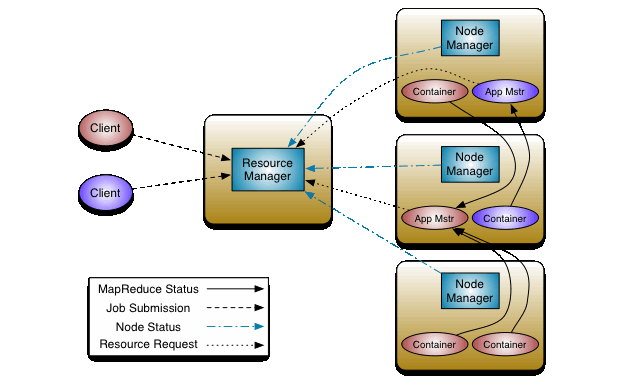
MapReduce
Model do przetwarzania dużych zbiorów danych. Składa się z części inspirowanych programowaniem funkcyjnym:
- Map – program mapujący, który pobiera dane z wejścia i dzieli ja na mniejsze podproblemy. Pozwala wybrać interesujący na pod zbiór danych który będzie ulegał dalszej obróbce
- Reduce – program zbierający dane i przedstawiający jest w interesującej nas formie. Zawiera często funkcje agregujące
- Combiner (Semi Reducer) - program podobny w działaniu do Reduce zbierający dane częściowe. Tworzony najczęściej w celu optymalizacji całego procesu MapReduce
- Driver – blok startowy całego procesu MapReduce. Określamy w nim jakie programy Map, Reduce , Combiner zostaną użyte w procesie. Określa również liczbę kopii Map , Combiner , Reduce wymaganych do działania całego procesu. Zawieramy w nim również ścieżkę wejściową na HDFS gdzie znajdują się dane wyjściowe oraz ścieżkę docelową na HDFS gdzie zapisane zostaną wyniki działania procesu MapReduce.
Popatrzmy dokładniej na ten model. Na schemacie 4 możemy zauważyć jak wygląda przepływ danych w takim procesie MapReduce. Dane początkowo trafiają do poszczególnych kopi programów Map. Następnie dane przekierowywane są do Combiner , który redukują liczbę potrzebnych danych w procesie. Etapem końcowym jest program Reduce , który zbiera wynik i przedstawia dane w formie docelowej. Hadoop wspiera uruchomienie programów MapReduce. Zadaniem programisty jest napisanie tylko poszczególnych programów Map, Combiner i Reduce. Konfiguracja samego procesu odbywa się w programie Driver, w którym informujemy Hadoop z jakich programów Map, Combiner , Reduce będziemy korzystać oraz określenie ilości liczby ich kopii oraz ścieżki wejściowej z danych oraz ścieżki docelowej na HDFS. Zapisem i odczytem danych na HDFS oraz przekierowaniem danych do poszczególnych programów Map, Reduce, Combiner zajmuję się już sam Hadoop zgodnie z konfiguracją w programie Driver.
Schemat 4
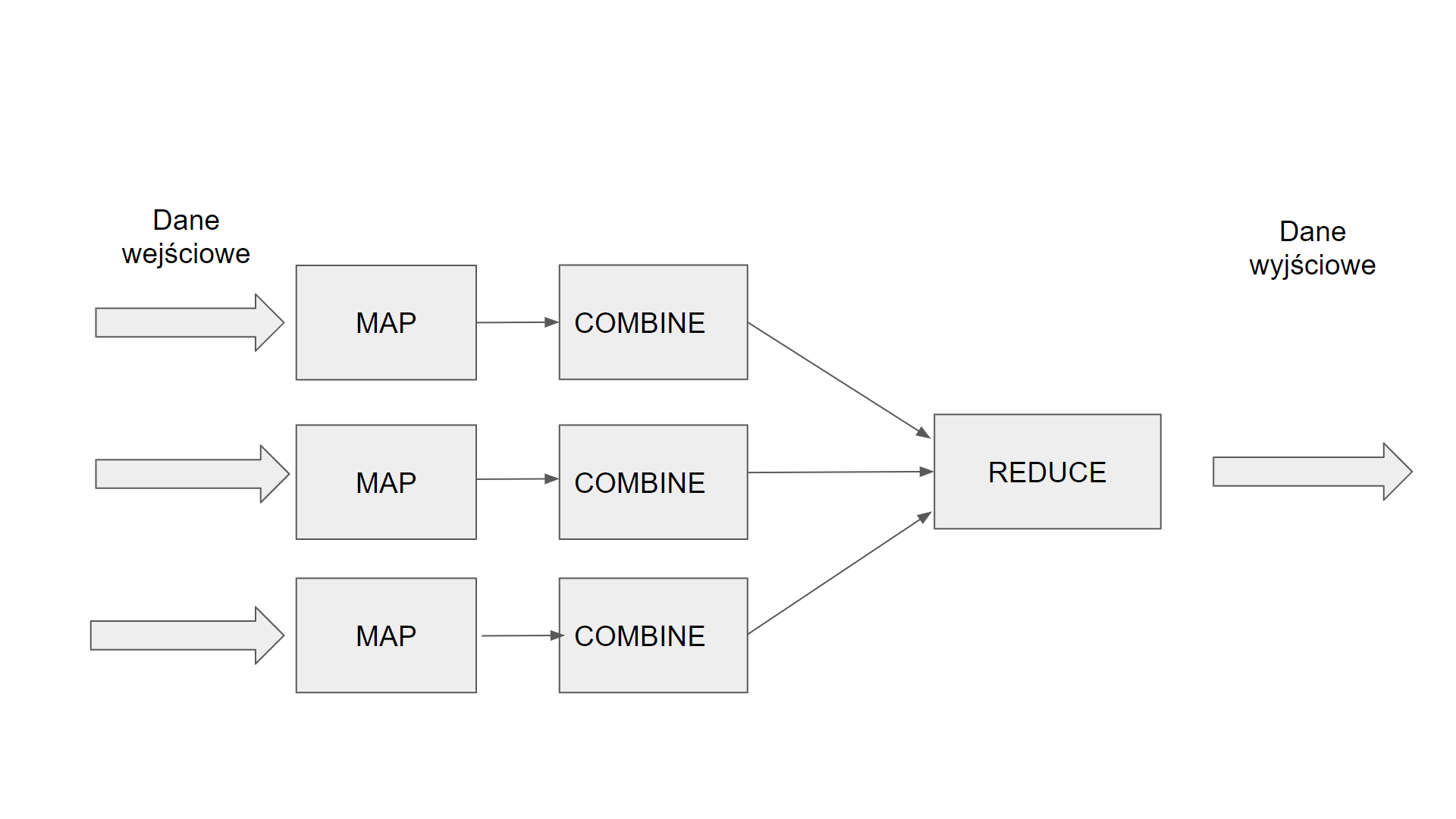
Klaster Hadoop w chmurze
Istnieje wiele możliwości uruchomienia takiego testowego klastra w chmurze. Wiele największych rozwiązań chmurowych wspiera rozwiązanie Hadoop i tak:
- Azure - https://azure.microsoft.com/en-us/services/hdinsight/
- AWS - https://aws.amazon.com/getting-started/projects/analyze-big-data/
- Google Cloud - https://cloud.google.com/dataproc/
Lokalny klaster Hadoop
Możemy uruchomić taki lokalny klaster na swoim komputerze. Istnieje kilka rozwiązań i tak:
Dla Windows:
- Sync Fusion - Big Data Platform https://www.syncfusion.com/products/big-data
Dla Linux:
- Hortonworks Data Platform https://hortonworks.com/products/data-platforms/hdp/ istnieje również sandbox na maszyny wirtualne https://hortonworks.com/downloads/#sandbox
- Cloudera - https://www.cloudera.com istnieje również vm quick start na maszyny wirtualne https://www.cloudera.com/downloads/quickstart_vms/5-13.html
- Docker
Poniżej pokażę jak uruchomić taki klaster za pomocą Docker na Linux (komendy są prezentowane dla dystrybucji Debian lub Ubuntu ale nie stoi nic na przeszkodzie by wykonać to na innych dystrybucjach po odpowiednim dostosowaniu komend).
W tym celu przygotowałem specjalne repozytorium na Github:
https://github.com/mrozim78/hadoop-net-presentation
Po ściągnięciu tego repozytorium w katalogu docker/images uruchamiamy skrypt:
./build_images.sh
Uruchomi to proces tworzenia się lokalnych obrazów Docker. Po zakończeniu procesu wchodzimy do katalogu docker/compose. Znajduje się plik konfiguracyjny do uruchomienia klastra Hadoop. By uruchomić tworzenie takiego klastra wraz z Docker potrzebujemy zainstalowanego programu docker-compose. By zbudować klaster wykonujemy komendę:
sudo docker-compose -f dev_all_open.yaml up -d
Do pliku /etc/hosts dopisujemy następujące linie:
127.0.0.1 namenode
127.0.0.1 nodemanager
127.0.0.1 datanode
127.0.0.1 historyserver
127.0.0.1 resourcemanager
Zapewni to nam odwołanie do odpowiednich węzłów klastra po nazwach.
W celu przetestowania czy klaster funkcjonuje uruchamiamy w przeglądarce stronę:
Praca z HDFS
W celu użycia kilku komend dla HDFS logujemy się do kontenera nodemanager (który utworzyliśmy za pomocą docker-compose):
./sudo docker exec -ti nodemanager /bin/bash
Poniżej prezentuje listę użytecznych komend dla HDFS
- Wylistowanie katalogu
hdfs dfs -ls {HDFS_PATH}
- Stworzenie katalogu
hdfs dfs -mkdir {HDFS_PATH}
- Usuwanie katalogu
hadoop fs -rm {HDFS_PATH}
- Kopiowanie pliku z dysku lokalnego na HDFS
hadoop fs -copyFromLocal {LOCAL_PATH} {HDFS_PATH}
- Kopiowanie pliku z HDFS na dysk lokalny
hadoop fs -copyToLocal {HDFS_PATH} {LOCAL_PATH}
- Kopiowanie między katalogami na HDFS
hadoop fs -cp {HDFS_PATH1} {HDFS_PATH2}
- Usuwanie pliku
hadoop fs -rm {HDFS_PATH}
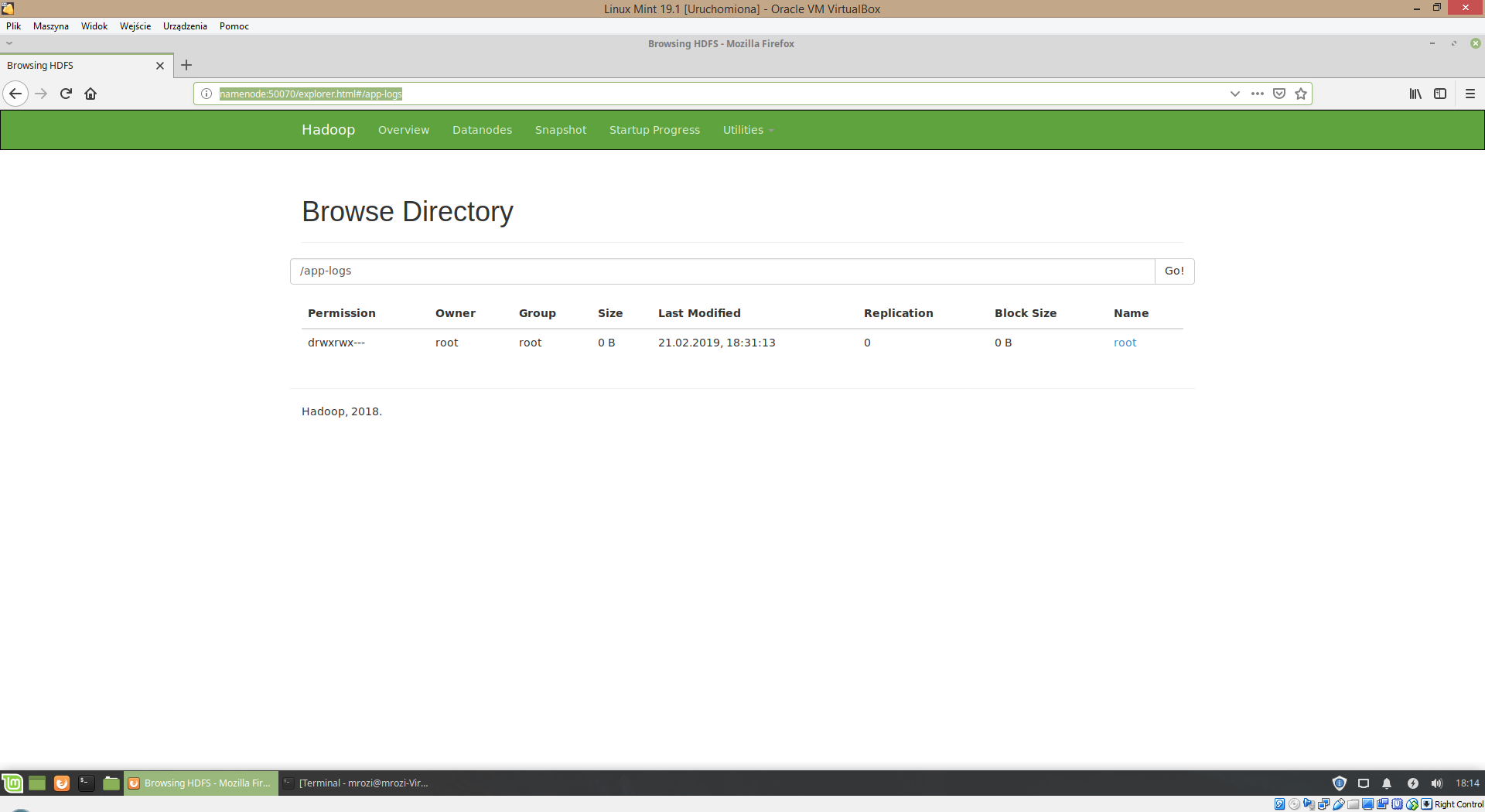
Istnieje także interfejs WWW dla systemu HDFS:
http://namenode:50070/explorer.html#
Umożliwia on tylko chodzenie po drzewie katalogów HDFS oraz ściąganie plików z HDFS.
Schemat 5
Następną możliwością pracy z systemem HDFS jest użycie interfejsu Rest Api. Szczegóły działania Rest Api dla HDFS możemy odszukać w:
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/WebHDFS.html
HDFS i .NET Core
W ściągniętym przez nas repozytorium w katalogu library odnajdziemy bibliotekę dostosowaną do .NET Standard 2.0 umożliwiającą dostęp do HDFS przez Rest Api (Hadoop.Net.Library.WebHdfs.Client). Zawarta jest tam także przykładowa aplikacja w .NET Core, która pokazuje przykłady jej użycia (Hadoop.Net.Library.Hdfs.Cmd).
Przykładowa aplikacja w .NET Core umożliwia dostęp do HDFS i obsługuje następujące operacje:
- Utworzenie katalogu
- Skasowanie katalogu lub pliku
- Wylistowanie obiektów (katalogu oraz plików) w katalogu na HDFS
- Uzyskanie informacji o obiekcie (katalogu oraz pliku) w HDFS
- Przesłanie pliku do HDFS z lokalnej ścieżki
- Pobranie pliku z HDFS do lokalnej ścieżki
Jako ścieżkę dostępu URL do HDFS powinniśmy podać w naszym wypadku:
Podsumowując, możemy zauważyć, że praca z Apache Hadoop nie jest tak skomplikowana jak mogła by się wydawać i daje duże możliwości w przetwarzaniu dużych zbiorów danych. Do skomplikowanych nie należy także postawienie takiego środowiska do testów na swoim komputerze. Następną istotną kwestią jest to, że pomimo iż platforma ta napisana jest w Javie i skierowana była głównie do rozwiązań opartych o Java, nie musi się ograniczać tylko do tego języka.
W następnej części skupimy się na pisaniu programów w MapReduce. Zaczniemy od pokazania takich programów w Java i przejdziemy płynnie do pisania takich programów w innych językach programowania. W naszym przypadku będzie to .NET Core.

Zobacz wszystkie artykuły tego autora