Wpłynąłem na suchego przestwór oceanu czyli o tych, którzy docierają do GraphX

(Prawie) każda prezentacja dotycząca Apache Spark zaczyna się od wykresu porównującego czas wykonania Logistic regression in Hadoop and Spark.
Nad wyższym słupkiem (tym od Hadoopa) widnieje liczba 110, nad niższym, ledwie zauważalnym (tym od Sparka) liczba 0.9. Run workloads 100x faster. Potem drugi obrazek - moduły Sparka: cztery ciemnoniebieskie prostokąty. Wychodzimy od RDD (Resilient Distributed Dataset), potem Spark SQL, Spark Streaming. Rzadziej coś konkretnego z MLib (machine learning) - w tym obszarze częściej, szybciej, łatwiej można pooglądać w Python i Keras albo innym Tensorflow czy PyTorch. Tylko nieliczni "zaglądają" do ostatniego klocka GraphX (graph).
A bo grafy to wąskie zastosowanie, a bo API oparte na "starym, niskopoziomowym" RDD (bez DataFrame/Dataset)... Ten ostatni zarzut można próbować odeprzeć wprowadzając bibliotekę GraphFrames (GraphX is to RDDs as GraphFrames are to DataFrames.) szczególnie z wykorzystaniem tzw. motif finding. Ten prosty DSL pozwala już na tworzenie pewnych wzorców wyszukiwania np. (a)-[e]->(b) czyli wierzchołków a i b połączonych krawędzią e.

Więcej? GraphFrames User Guide
Czuć jednak pewien niedosyt a do tego głosy z sali:
- "Nie potrzebuję bazy grafowej bo nie będę pisał kolejnego portalu społecznościowego",
- "Nie budujemy systemu na potrzeby transportu żeby szukać najkrótszych ścieżek".
- "ZG8gZHVweQ=="
a przecież wszystko jest grafem! Relacje między osobami, zakupy, faktury:

I do tego The whiteboard model is the physical model. Musimy rozbudować model? Dodać albo zmienić zależności? Dodajmy bez tych ![]()
Wszystko jest grafem! Cały świat jest grafem! "Wybuch mózga!" (Chodzi o gwałtowną produkcję któregoś z hormonów, które często przytrafia się dzieciom kiedy muszą iść spać. Tak to zjawisko nazywa nasz 8-letni syn W***k).
Wóz nurza się w zieloność i jak łódka brodzi czyli czym jest Cypher
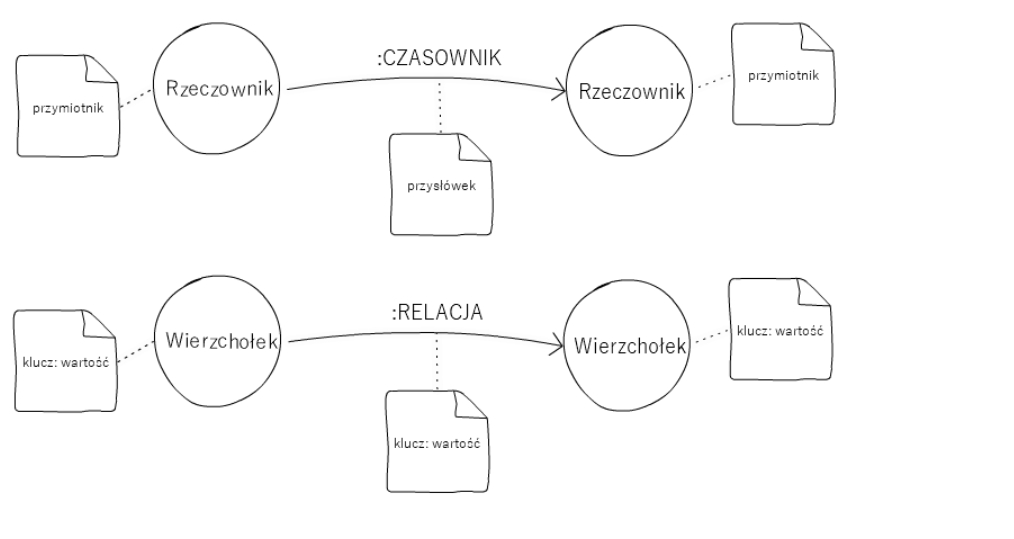
Truizmem jest stwierdzenie, że graf składa się z wierzchołków i krawędzi. Wierzchołki definiują nam pewien byt (osobę, miejsce, rzecz, kategorię itd.), krawędzie relacje między wierzchołkami czyli jak te wierzchołki są ze sobą połączone ("jestem żonaty z", "mieszkam w", "znam", "lubię", "jestem właścicielem" itd.). W przypadku bazy Neo4j każdy wierzchołek może mieć wiele etykiet (label), które określają jego typ. Każdy wierzchołek i krawędź mogą zawierać dodatkowe atrybuty (properties) co tworzy nam tzw. property graph. Przekładając opis naszych danych w języku naturalnym na schemat bazy:
- rzeczownik (noun) to etykieta/typ wierzchołka (label)
- przymiotnik (adjective) to atrybut (property) wierzchołka
- czasownik (verb) to nazwa relacji
- przysłówek (adverb) to atrybut (property) krawędzi
Cypher jest deklaratywnym językiem zapytań, który umożliwia nam wyszukiwanie i modyfikację danych grafowych. Pierwotnie stworzony na potrzeby bazy Neo4j, lidera w rankingu baz grafowych, dla wielu praktycznie synonimu takiej bazy. W skrócie można powiedzieć, że jest "eskuelem dla grafów". Słowa kluczowe WHERE czy ORDER BY inspirowane właśnie są przez SQL. Język czerpie także ze SPARQL (pattern matching) czy Haskella i Pythona. Cypher jest dość intuicyjny i human-readable. Z racji tego, że nawiasy okrągłe () reprezentują wierzchołki a --> krawędzie w opisie przewija się nawet sformułowanie o ASCII art.
Jednym z najprostszych zapytań będzie

które zwróci wszystkie wierzchołki () w naszym grafie.

zwróci tylko wierzchołki typu Person (wierzchołki, które mają określoną etykietę Person) i zawęzi wynik do 10 elementów.

to osoby urodzone w 1970 r. (atrybut born jest równy 1970).
Bardziej skomplikowane warunki wymagają wprowadzenia klauzuli WHERE

Istotą grafu są jednak relacje.

to nazwiska (zwracamy jedynie atrybut name a nie cały wierzchołek) osób, które zagrały (relacja ACTED_IN) w filmie (wierzchołek typu Movie) pod tytułem "The Matrix" (wartość atrybutu title).
Aktorzy to nie jedyne osoby, które są związane z danym filmem. Są jeszcze producenci, reżyserzy... - istnieją zatem różne relacje łączące wierzchołki typu Person i Movie.

A jeśli interesuje nas lista (collect) reżyserów (relacja DIRECTED) określonego filmu?

Więcej? Introduction to Neo4j Online Course and Tutorial
Patrzę w niebo, gwiazd szukam, przewodniczek łodzi czyli o nowości(ach) w Spark 3.0
Gdzieś na horyzoncie majaczy już Spark 3.0. Coś staje się "deprecated", ktoś twierdzi że będzie 17x szybszy (teraz ten niższy słupek już w ogóle będzie niezauważalny).
Jednym z przegłosowanych już propozycji tzw. Spark Project Improvement Proposal (SPIP) jest realizacja Property Graphs, Cypher Queries, and Algorithms.
The idea is to define a Cypher-compatible Property Graph type based on DataFrames; to replace GraphFrames querying with Cypher; to reimplement GraphX/GraphFrames algos on the PropertyGraph type.
Spróbujmy zatem skorzystać z mocy silnika Spark i elegancji języka Cypher w nowej odsłonie zwanej Spark Graph (w oparciu o projekt Morpheus)
Słyszę, kędy się motyl kołysa na trawie czyli coś się wykona...
Na potrzeby demo zdefiniujmy abstrakcyjny zbiór pracowników (wierzchołki z etykietą Employee) o abstrakcyjnych danych (atrybuty name i salary) i równie abstrakcyjnych relacjach między nimi (LIKES z atrybutem rating od 1 do 5).
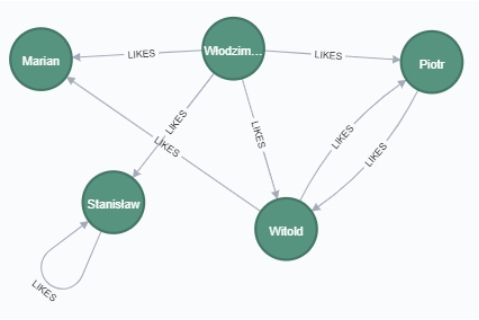
Teraz już tylko nasz program, z jakżeż pięknymi (za)pytaniami, które sobie stawiamy...


... i otrzymanymi odpowiedziami jako wynik wykonania!

Jedźmy, nikt nie woła czyli podsumowanie...
Apache Spark jest obecnie w wersji 3.0.0-preview2 a Issue SPARK-25994 ma status OPEN.
Może jednak w niedługiej przyszłości prezentacje będą już wyglądały inaczej.
https://github.com/wkozi/grafomania
