Generowanie danych syntetycznych dla modeli OCR i NLP

Rozwój uczenia maszynowego w przetwarzaniu dokumentów napotyka na stały problem – dostęp do danych treningowych. Modele wymagają tysięcy oznaczonych przykładów, a pozyskanie prawdziwych dokumentów biznesowych jest trudne lub niemożliwe.
Dane klientów podlegają wielu ograniczeniom, w tym między innymi RODO. Publiczne zbiory danych rzadko zawierają interesujące nas dokumenty z poprawnie oznaczonymi encjami. Nawet gdy uda się zdobyć surowe pliki, ich adnotacja wymaga znacznych nakładów czasu i środków.
Jednym z rozwiązań tego problemu jest generowanie danych syntetycznych. Podejście to polega na tworzeniu sztucznych dokumentów, które zachowują strukturę i format prawdziwych, ale wypełnione są losowymi, jednak w dalszym ciągu zmyślonymi danymi. Numery NIP z prawidłową sumą kontrolną, adresy z istniejących miejscowości, daty w odpowiednich formatach.
W tym wpisie przedstawiamy dwa podejścia do automatycznego generowania takich zbiorów treningowych. Oba stosujemy w produkcyjnych projektach przetwarzania dokumentów.

Rysunek 1 Przykład wypełnionego szablonu, przygotowanego pod generowanie danych

Rysunek 2 Wygenerowany szablon z wypełnionymi polami
Podejścia do generowania danych
W zależności od docelowego zastosowania, generowanie danych syntetycznych wymaga różnych formatów wejściowych i wyjściowych. Modele VLM (Vision Language Models) stosowane do ekstrakcji danych z dokumentów potrzebują obrazów z oznaczonymi współrzędnymi tekstu lub dokumentów z metadanymi opisującymi zawarte encje.
Opracowaliśmy dwa generatory, które odpowiadają na te potrzeby. Oba korzystają ze wspólnej bazy encji i słowników do generowania wartości. Różnią się formatem szablonów oraz strukturą wyjścia.
Generator PNG przyjmuje szablon w postaci obrazu oraz plik JSON definiujący współrzędne pól i typy encji do wygenerowania. Na podstawie konfiguracji generuje wartości encji (imiona, daty, numery dokumentów), a następnie wpisuje je w odpowiednie miejsca na obrazie. Wynikiem jest dokument PDF oraz plik JSON z wygenerowanymi wartościami i ich współrzędnymi.
Generator DOCX wykorzystuje szablony dokumentów Word z placeholderami oraz plik JSON definiujący listę encji. Generuje wartości encji i podstawia je w miejsce placeholderów. Eksportuje wypełniony dokument do DOCX lub PDF wraz z plikiem JSON zawierającym wygenerowane wartości. Podejście to sprawdza się w treningu modeli VLM oraz systemów ekstrakcji informacji.
Rysunek 3 Diagram przepływu dla generatorów
Kluczowa różnica: generator PNG operuje na współrzędnych pikselowych i produkuje obrazy z ground truth dla OCR. Generator DOCX operuje na strukturze dokumentu Word i produkuje pliki gotowe do dalszego przetwarzania.
Zasada działania generatorów
Oba generatory działają według tej samej logiki: przyjmują szablon dokumentu; identyfikują pola do wypełnienia; generują wartości encji ze wspólnej bazy, a następnie zapisują wynik wraz z metadanymi. Różnica polega na formacie plików wejściowych i wyjściowych.

Rysunek 4 Dane wejściowe do generatora PNG

Rysunek 5 Dane wejściowe do generatora DOCX
Generator PNG przyjmuje na wejściu obraz szablonu oraz plik JSON definiujący współrzędne pól (x1, y1, x2, y2), typ encji i numer strony. Na wyjściu produkuje obraz z wypełnionymi przekonwertowany na dokument PDF polami oraz JSON z wygenerowanymi wartościami.

Rysunek 6 Przykład koordynatów dla wartości "imię"
Generator DOCX przyjmuje na wejściu dokument Word z placeholderami {nazwa_encji} oraz plik JSON z listą encji. Na wyjściu produkuje wypełniony dokument DOCX lub PDF oraz JSON z wygenerowanymi wartościami.

Rysunek 7 Przykład placeholderów dla wartośc "numer_zaswiadczenia", "imie i nazwisko" oraz "data urodzenia"

Rysunek 8 Wygenerowany plik
Generator PNG oferuje większe możliwości konfiguracji. Obsługuje typy pól takie jak "text" (wpisanie wartości z automatycznym dopasowaniem czcionki), "rectangles" (rozbicie na pojedyncze znaki w osobnych polach), "complex" (rozłożenie encji na wiele obszarów) oraz "choice" (losowy wybór wariantu). Wymaga jednak przygotowania współrzędnych dla każdego pola, co zwiększa nakład pracy przy tworzeniu szablonu.

Rysunek 9 Przykład typu pola "rectangles"
Generator DOCX jest prostszy w użyciu. Wystarczy umieścić placeholdery w dokumencie Word. Obsługuje postprocessory do warunkowego wypełniania pól i zależności między encjami. Ograniczeniem jest operowanie na strukturze dokumentu Word bez kontroli nad dokładnym położeniem tekstu.
Wspólna baza encji
Oba generatory korzystają ze wspólnej klasy CustomEntityGenerator oraz biblioteki Faker z lokalizacją polską. Baza zawiera generatory dla typowych encji występujących w dokumentach biznesowych.
Dane identyfikacyjne obejmują NIP z prawidłową sumą kontrolną, REGON w wersji 9 i 14 cyfrowej, PESEL oraz numery dowodów osobistych. Dane osobowe to imiona i nazwiska z polskich słowników, adresy email oraz numery telefonów w polskich formatach. Dane adresowe zawierają ulice, numery budynków, kody pocztowe, miasta i województwa. Dane czasowe to daty w różnych formatach, godziny oraz poszczególne składowe dat. Dane liczbowe obejmują kwoty, numery dokumentów oraz wartości procentowe.

Rysunek 10 Przykład funkcji generującej pesel w CustomEntityGenerator
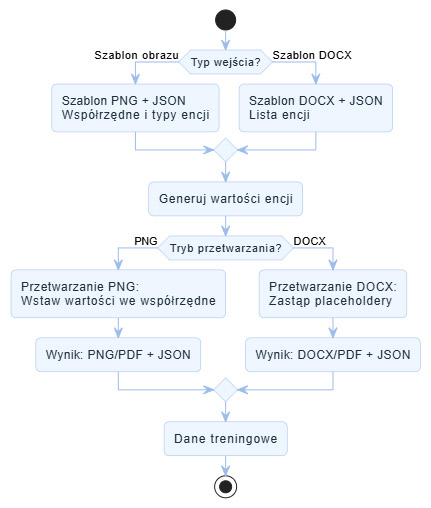
Dodanie nowej encji wymaga zdefiniowania funkcji generującej w CustomEntityGenerator oraz wpisu w SupportedEntities z odpowiednim wzorcem regex.
Rysunek 11 Przykład wpisu zmiennej w SupportedEntities
Podsumowanie
Dane syntetyczne stanowią praktyczne rozwiązanie problemu dostępności zbiorów treningowych w projektach przetwarzania dokumentów. Pozwalają na szybkie rozpoczęcie pracy nad modelem bez konieczności pozyskiwania i adnotacji prawdziwych dokumentów. Należy jednak pamiętać, że dane syntetyczne powinny stanowić punkt wyjścia, a nie jedyną podstawę treningu. Ostateczna ewaluacja modelu wymaga testów na podzbiorze rzeczywistych dokumentów, które oddają pełną zmienność danych produkcyjnych.
Generowanie 1000 dokumentów OL‑9 – instrukcja krok po kroku
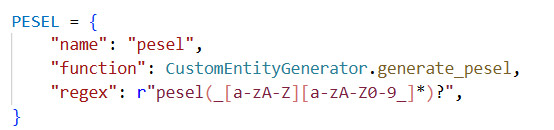
Generujemy 1000 różnych instancji formularza OL‑9 („Zaświadczenie o stanie zdrowia pacjenta”) na podstawie dwóch plików PNG (strony 0 i 1) oraz jednego pliku JSON zawierającego definicję pól i współrzędne.

Sposób zdefiniowania szablonu pliku json
- Przygotowanie obrazu i odczyt współrzędnych
- Otwórz skan formularza w dowolnym edytorze grafiki (np. Paint).
- Dla każdego pola narysuj prostokąt: zaczynając od lewego górnego rogu (x1,y1) do prawego dolnego (x2,y2). Zapisz współrzędne w pikselach.
- Numeracja stron zaczyna się od 0 (pierwsza strona → page: 0, druga → page: 1).
- Jeżeli opcja pola ma być pusta – w JSON użyj typu empty i nie podawaj współrzędnych.
- Schemat JSON pola
Każde pole opisujemy rekordem zawierającym przynajmniej: name (identyfikator), page (numer strony), type (np. text, choice, rectangles, complex, tick, empty), coords (tablica [x1,y1,x2,y2], opcjonalna dla empty) oraz entity_type (rodzaj encji do wygenerowania).
Dla pól podstawowych (np. imie, nazwisko) struktura jest taka sama; zmienia się jedynie name, coords i entity_type. Przykład dla danych adresowych znajduje się poniżej.


- Przykład pola „numer telefonu” (opis)
W JSON definiujemy pole typu choice z dwiema opcjami:
- nie – typu empty, brak współrzędnych, pole nie jest wypełnione.
- tak – zawiera name: telefon i entity_type: text, generator wstawi numer telefonu w danym prostokącie.


- Pola dzielone na kratki (data urodzenia, PESEL)
Dla pól rozbitych na pojedyncze cyfry używamy rectangles (liczba kratek), w przypadku pól jak data urodzenia wykorzystujemy complex z trzema subfields dla daty: day, month, year, które również są w typie rectangles. Generator automatycznie rozdziela wartości po poszczególnych kratkach.



- Pola słownikowe
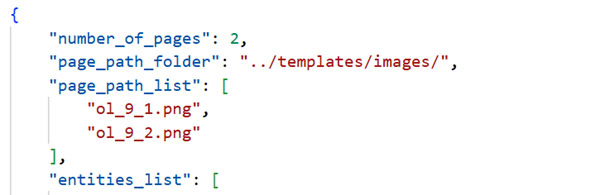
Jeśli wartość nie jest typową encją generowaną przez Faker (np. opis choroby), dodajemy dedykowany słownik w pliku default_possible_entities.json.

Przykładowy klucz: choroba_podstawowa.
Następnie:
- dodaj klucz/enum w enums.py

- napisz funkcję losującą wartości w custom_entity_generator.py

- zarejestruj encję w supported_entities_enum.py

Pole choroba_podstawowa może występować zawsze; choroba_wspolistniejaca warto zdefiniować jako choice (może być puste). Aby uniknąć powtórzeń, można dopisywać sufiksy _2, _3 dla kolejnych wystąpień.

Druga strona dokumentu OL-9.

- Postępuj analogicznie: zdefiniuj współrzędne i typy pól. Dla pól „Opis choroby” i „Rokowanie” dodaj osobne słowniki w default_possible_entities.json.
Pola typu wybór: użyj choice z wariantami, gdzie warianty będą miały type: "tick" (oznaczenie zaznaczenia).


Stwórz plik tekstowy zawierający treść formularza i wstaw placeholdery w miejscach danych: na przykład {imie}, {nazwisko}, {pesel}, {choroba_podstawowa}.
Generator zastąpi placeholdery wygenerowanymi encjami i umieści je w zadeklarowanych prostokątach zgodnie z JSON. Fragment pliku tekstowego poniżej.
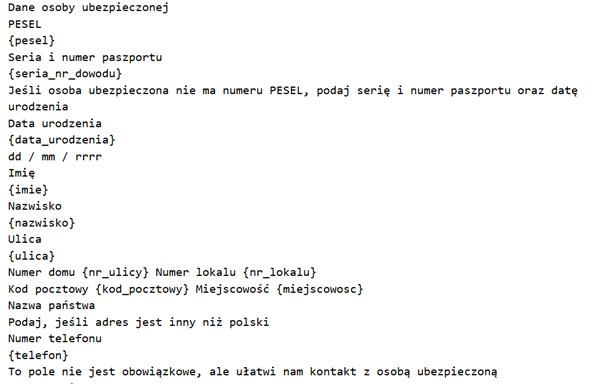
Postać wygenerowanego dokumentu znajduje się poniżej. Dane w polu „opis choroby” oraz „rokowanie” zostały wygenerowane przy użyciu AI i nie odzwierciedlają rzeczywistości. Wszystkie informacje zawarte w dokumencie są nieprawdziwe.


Link do githuba: asseco-tech/GOLEMator

