Voice AI od podstaw: modele ASR i TTS czyli fundament naturalnej komunikacji człowieka z maszyną

Głos to jeden z kluczowych kanałów kontaktu z klientem szczególnie tam, gdzie liczy się szybkość i możliwość załatwienia sprawy od ręki. Dla systemów AI to ogromna szansa, ale też znacznie większe wyzwanie niż w przypadku chatu.
Rozmowy głosowe trudniej się skalują: jakość nagrań bywa nierówna, wypowiedzi są nieprecyzyjne, rozmówcy wchodzą sobie w słowo, a nad całością unosi się presja czasu i zachowania naturalnego odczucia rozmowy.
W systemach głosowej sztucznej inteligencji kluczową rolę odgrywają modele ASR (rozpoznawanie mowy) i TTS (synteza mowy). Choć ich zadanie można opisać prosto, zamiana mowy na tekst i tekstu na mowę, w praktyce muszą one poradzić sobie z hałasem, różnymi stylami mówienia, tempem, kontekstem językowym oraz trudnymi elementami, jak nazwy własne czy słownictwo domenowe.
W tym artykule pokażemy, co faktycznie dzieje się „pod maską” modeli ASR i TTS, jakie decyzje architektoniczne stoją za ich działaniem oraz skąd biorą się ich mocne strony i ograniczenia w realnych wdrożeniach biznesowych.
Źródła niepewności w systemach głosowych
Najczęstszym kanałem głosowym w obsłudze klienta wciąż pozostaje telefon i to właśnie tam najszybciej ujawniają się ograniczenia technologii. Spadek jakości i wydłużenie czasu obsługi zaczynają się już na poziomie samego sygnału audio. Typowe rozmowy telefoniczne są wąskopasmowe (8 kHz), przechodzą przez kompresję i różne kodeki, przez co tracą część informacji istotnych dla precyzyjnego rozróżniania głosek. Do tego dochodzą szumy tła, ulica, biuro, wiatr, inne rozmowy oraz duża zmienność po stronie użytkowników: różna odległość od mikrofonu, tryb głośnomówiący, słabszy sprzęt czy niestabilne połączenie.
Człowiek zazwyczaj nadal „wyłapie sens” wypowiedzi. Dla modelu ASR oznacza to jednak wzrost niepewności i większe ryzyko błędów, szczególnie w nazwach własnych, liczbach czy krótkich słowach. Każda taka pomyłka to dodatkowe dopytania i potwierdzenia, a więc dłuższa rozmowa. W praktyce nie chodzi więc tylko o to, czy model działa, ale jak stabilnie radzi sobie z degradacją sygnału i na ile utrzymuje zrozumiałość w warunkach dalekich od laboratoryjnych.
Jak rozmowa zamienia się w dane
Dla człowieka rozmowa to głos i znaczenie. Dla modelu ASR to przede wszystkim sygnał jako ciąg próbek amplitudy w czasie, czyli fala dźwiękowa zapisana jako liczby. Jak wspomnieliśmy wcześniej w telefonii audio często ograniczone jest do 8khz co oznacza, że zgodnie z twierdzeniem Nyquista-Shannona sygnał nie zawiera informacji powyżej ~4 kHz. Niestety istotne detale części spółgłosek syczących i szeleszczących znajdują się poza tym zakresem, więc model dostaje mniej wskazówek akustycznych i musi silniej opierać się na kontekście językowym.
Surowa fala nie jest jednak wygodna do przetwarzania w sieci neuronowej. Dlatego w ASR najczęściej przekształca się ją do reprezentacji TFR (ang. Time-Frequency Representation), która pokazuje, jak energia rozkłada się w różnych pasmach w czasie. Proces przetwarzania sygnału audio wygląda następująco:
Framing
Sygnał dzieli się na krótkie, częściowo nachodzące na siebie ramki (np. długości 20-25 ms),
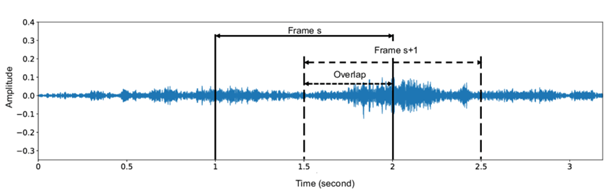
STFT (Short-Time Fourier Transform)
Dla każdej z ramek obliczamy dyskretną transformatę Fouriera. Otrzymujemy w ten sposób współczynniki opisujące udział poszczególnych częstotliwości w danym oknie czasowym, na podstawie których obliczamy moc widma.
Projekcja na skalę Mel
Pełne widmo ma liniową rozdzielczość częstotliwości, która nie odpowiada percepcji człowieka. Dlatego mapowane jest na skalę mel (większa rozdzielczość w niższych pasmach, mniejsza w wyższych)
Logarytm i normalizacja
Logarytm kompresuje dynamikę amplitudy i w połączeniu z normalizacją stabilizuje dane i ogranicza wpływ zmian głośności.
Rezultatem jest macierz, którą traktować można jako „obraz” dźwięku i modelować za pomocą sieci neuronowej.
Jak współczesny ASR zamienia dźwięk w tekst
Nowoczesne systemy rozpoznawania mowy bardzo często opierają się na architekturze enkoder-dekoder językowy warunkowany audio (ang. Attention Encoder–Decoder, AED). To podejście spopularyzowały modele w stylu OpenAI Whisper czy Nvidia Canary: jedna część modelu „rozumie” sygnał akustyczny, druga generuje tekst, korzystając zarówno z audio, jak i z kontekstu dotychczas wygenerowanego tekstu.
Aby użyć modelu ASR na początek należy najpierw wczytać go do pamięci podręcznej naszej karty graficznej (o ile taką posiadamy):

Wynik cuda:0 oznacza, że model został poprawnie załadowany na pierwszą kartę graficzną i będzie wykonywał obliczenia na GPU.
Encoder: od reprezentacji akustycznej do cech mowy
Wejściem do encodera jest log-mel spectrogram opisany wcześniej. Dla uproszczenia możemy użyć implementacji zawartej w ramach modelu:
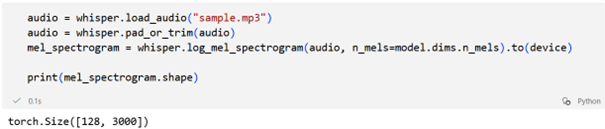
Wynik torch.Size([128, 3000]) oznacza, że powstał log-mel spektrogram o 128 pasmach mel i 3000 ramkach czasowych (30 s audio). To tensor prawue gotowy jako wejście do encodera modelu, należy dodać jedynie informację o ilości próbek które będzie przetwarzał model.

Encoder przekształca tę sekwencję w ciąg wektorów osadzeń (embeddingów), które opisują, co mogło zostać wypowiedziane i w którym fragmencie czasu.

Wynik (1500, 1280) oznacza, że encoder wygenerował:
1500 kroków czasowych (zagregowane fragmenty audio), 1280-wymiarowe embeddingi dla każdego kroku.
To sekwencja reprezentacji akustycznych przekazywana dalej do dekodera.
Dekoder: model języka warunkowany audio
Dekoder działa jak model języka, ale z dodatkowym dostępem do informacji akustycznej.
W każdym kroku:
widzi dotychczas wygenerowane tokeny, bierze pod uwagę wyjście encodera przez mechanizm uwagi przewiduje kolejny token.
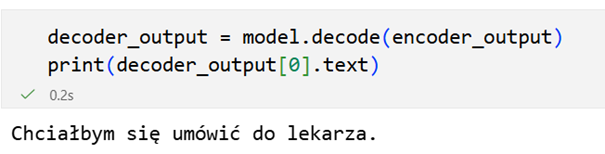
Wywołanie model.decode(encoder_output) uruchamia proces autoregresyjnego generowania tekstu na podstawie embeddingów audio. Model analizuje kontekst akustyczny i językowy, a następnie zwraca gotową transkrypcję.
Tokenizacja: dlaczego model nie przewiduje „słów”
Modele ASR nie generują bezpośrednio słów. Zamiast tego przewidują tokeny.
Dlaczego?
łatwiejsze skalowanie na wiele języków, radzenie sobie z rzadkimi i nowymi słowami, brak konieczności utrzymywania zamkniętego słownika.
W efekcie model może złożyć nowe słowo z mniejszych fragmentów, zamiast traktować je jako błąd.
Dekodowanie w inferencji: jak wybierany jest tekst
W środowisku produkcyjnym dekoder generuje transkrypcję w sposób autoregresyjny. Oznacza to, że tekst powstaje krok po kroku: w każdym etapie model przewiduje kolejny token na podstawie wcześniej wygenerowanych tokenów oraz reprezentacji audio z encodera. Innymi słowy, każda decyzja jest warunkowana historią. To, co już zostało zapisane, wpływa na to, co może pojawić się dalej. Proces kończy się w momencie wygenerowania specjalnego tokenu końca sekwencji albo osiągnięcia limitu długości.
Pozostaje jednak pytanie: jak dokładnie wybierany jest ten „kolejny” token, skoro model w każdym kroku rozważa wiele możliwych kontynuacji?
Najprostsza strategia to:
Greedy decoding - w każdym kroku wybieramy najbardziej prawdopodobny token.
W praktyce często stosuje się:
Beam search - utrzymuje kilka najlepszych hipotez równolegle, co zmniejsza ryzyko zapętlenia, powtórzeń lub przedwczesnego zakończenia transkrypcji.
W dłuższych nagraniach beam search potrafi istotnie poprawić stabilność generacji, szczególnie przy trudnym audio.
Jak współczesny TTS zamienia tekst w naturalną mowę
Wiemy już, jak z pomocą modeli rozpoznawania mowy zamienić możemy audio w tekst. Teraz skupimy się na tym jak odwrócić ten proces. Zadanie generowania mowy jest znacznie trudniejsze. Oprócz wygenerowania poprawnego głosu model musi kontrolować również rytm, tempo, akcent i prozodię.
Mowa jako sekwencja tokenów
Nowoczesny kierunek modeli generowania mowy mocno czerpie z doświadczeń zdobytych w dziedzinach przetwarzania języka naturalnego oraz rozpoznawania mowy. Zamiast generować falę audio bezpośrednio, twórcy modeli coraz częściej zamieniają mowę na dyskretne tokeny i traktują syntezę mowy jako problem modelowania sekwencji.
Neural audio codec: jak mowa staje się tokenami
Kluczowym elementem pozwalającym osiągać naturalnie brzmiący syntetyczny głos jest mechanizm neural audio codec. To rodzaj tokenizera audio kompresujący mowę do reprezentacji dyskretnych w sposób który umożliwia rekonstrukcję fali dźwiękowej. Pozwala to traktować dźwięk jako sekwencję symboli co jest formatem idealnym do modelowania za pomocą sieci neuronowych typu Transformer. Najczęściej spotykaną techniką dyskretyzacji w neural audio codec jest Residual Vector Quantization (RVQ), w której kolejne codebooki (kwantyzatory) doprecyzowują reprezentację sygnału.
Kluczowymi parametrami są częstotliwość tokenów (Hz) opisująca ile tokenów składa się na jedną sekundę audio oraz liczba codebooków czyli ile równoległych książek kodowych współtworzy dyskretną reprezentację dźwięku.
Poniższy przykład pokazuje w praktyce, jak fala dźwiękowa zamieniana jest na tokeny, a następnie rekonstruowana z powrotem do postaci audio:
Ładujemy model EnCodec (24 kHz) i ustawiamy docelowy bitrate, który wpływa na jakość i liczbę tokenów.
EnCodec posłuży nam wyłącznie jako demonstracyjny przykład neural audio codec, pokazujący, jak wygląda docelowy format tokenów audio, które w praktycznym systemie TTS będą generowane przez model sekwencyjny (najczęściej Transformer). W innych architekturach tokenizer może mieć inną częstotliwość, liczbę codebooków lub inny detokenizer, lecz schemat działania systemu pozostaje bez zmian.

Konwertujemy plik do formatu oczekiwanego przez codec (24 kHz, mono) i dodajemy wymiar batch wskazujący liczbę próbek które przetwarzamy.

Model kompresuje audio do indeksów codebooków.
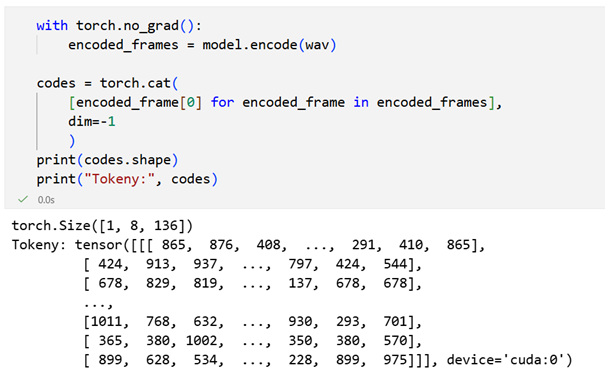
Tensor ma wymiar [1, 8, 136], co oznacza jedną próbkę audio zakodowaną przy użyciu 8 codebooków oraz 136 dyskretnych kroków czasowych.
Tensor codes zawiera dyskretne indeksy codebooków. Każdy wiersz odpowiada jednej warstwie kwantyzacji, a każda kolumna kolejnemu krokowi czasowemu. Wartości są identyfikatorami wektorów z książek kodowych, które wspólnie opisują strukturę akustyczną sygnału.
Modelowanie sekwencji
To właśnie ta dyskretna sekwencja indeksów codes jest obiektem modelowania w systemach TTS. Model sekwencyjny (LM/LLM, np. Transformer) nie generuje bezpośrednio fali audio, tylko przewiduje kolejne tokeny audio (indeksy codebooków) w czasie.
Rekonstrukcja audio
Ostatnim i zarazem najbardziej wrażliwym etapem jest rekonstrukcja mowy na podstawie wygenerowanych tokenów audio.
Na podstawie takiej sekwencji dekoder neural codec może odtworzyć sygnał dźwiękowy:

Otrzymany tensor oznacza
- 1 – batch size,
- 1 – liczba kanałów (mono),
- 43520 – liczba próbek audio.
Przy częstotliwości próbkowania 24 kHz odpowiada to około:
Oznacza to, że z sekwencji zaledwie 136 kroków czasowych (tokenów) udało się odtworzyć ponad 1.8 sekundy ciągłego sygnału audio.
W torze kodekowym (jak w tym przykładzie) „detokenizerem” jest dekoder samego neural audio codec, który bierze tokeny i rekonstruuje falę audio bardzo szybko, co sprzyja małemu opóźnieniu. W części nowoczesnych systemów spotyka się jednak inny wariant. Tokeny audio są wejściem do osobnego vocodera generatywnego (np. model dyfuzyjny lub flow matching), który potrafi dać bardzo wysoką jakość kosztem większej złożoności inferencji.
Aby umożliwić działanie syntezy mowy w czasie rzeczywistym, rekonstrukcję prowadzi się zwykle w trybie strumieniowym. Sam model sekwencyjny, który generuje tokeny mowy autoregresyjnie, naturalnie nadaje się do pracy strumieniowej. Wąskim gardłem bywają natomiast vocodery dyfuzyjne lub oparte o flow matching, które generują wynik iteracyjnie i często wymagają „przejścia” po całym fragmencie audio.
Rozwiązaniem tego problemu jest mechanizm block-wise flow matching/diffusion. Tokeny dzieli się na krótkie okna, do każdego okna dokleja się niewielki bufor kontekstu z poprzedniego fragmentu, a wygenerowane kawałki fali częściowo się nakłada i łączy tak, żeby ukryć przejścia pomiędzy fragmentami.
Podsumowanie
W świecie Voice AI liczy się nie tylko to, czy model „umie” rozpoznać lub wygenerować mowę, ale czy robi to stabilnie w realnych warunkach. W artykule rozebraliśmy na czynniki pierwsze, co dzieje się „pod maską” w dwóch kluczowych komponentach: ASR (rozpoznawanie mowy) i TTS (synteza mowy), pokazując skąd biorą się ograniczenia i jak decyzje architektoniczne przekładają się na jakość i latencję.
Co osiągnęliśmy?
- Nazwaliśmy źródła niepewności w systemach głosowych: wąskopasmowy kanał telefonu, kompresja i szumy zwiększają ryzyko błędów ASR, co w praktyce wydłuża rozmowę przez dopytania.
- Pokazaliśmy, jak rozmowa w postaci fali audio jest przetwarzana do formatu zrozumiałego dla sieci: po framingu i przejściu przez STFT oraz skalę mel otrzymujemy reprezentację czas–częstotliwość, która stanowi podstawę dalszego modelowania.
- Prześledziliśmy nowoczesny tor ASR (AED): encoder zamienia log-mel w sekwencję embeddingów, a decoder działa jak model języka warunkowany audio i generuje transkrypcję autoregresyjnie.
- Omówiliśmy, jak model wybiera tekst w inferencji: dlaczego przewiduje tokeny (a nie „słowa”) oraz jak strategie dekodowania wpływają na stabilność i jakość w trudnym audio.
- Odwróciliśmy perspektywę dla TTS: pokazaliśmy nowoczesny schemat zamiany tekstu w tokeny mowy za pomocą neural audio codec wyznaczając format docelowych tokenów stanowiących cel modelowania sekwencji.
Czego się nauczyliśmy?
- Voice AI to w dużej mierze sztuka zarządzania niepewnością sygnału i świadomego dobierania kompromisów między jakością, latencją i stabilnością.
- Zarówno w ASR, jak i w TTS, kluczowe jest to, że modele pracują na sekwencjach tokenów/embeddingów, a nie „magicznie” na słowach czy fali.
- „Naturalność” w TTS to nie tylko poprawne fonemy, ale też rytm/tempo/akcent/prozodia, dlatego architektury często rozdzielają modelowanie sekwencji i rekonstrukcję audio.
Na koniec warto podkreślić, że to, co pokazaliśmy, to dopiero wierzchołek góry lodowej. Teraz, gdy masz już solidne podstawy, możesz zgłębiać kolejne architektury, ich zalety oraz ograniczenia. Dzięki temu szybciej zaczniesz dostrzegać, skąd biorą się różnice między rozwiązaniami i świadomie podejmować decyzje projektowe przy budowie własnych rozwiązań głosowych.
